最近发布
View All → Jun 11, 2026 AI Agent
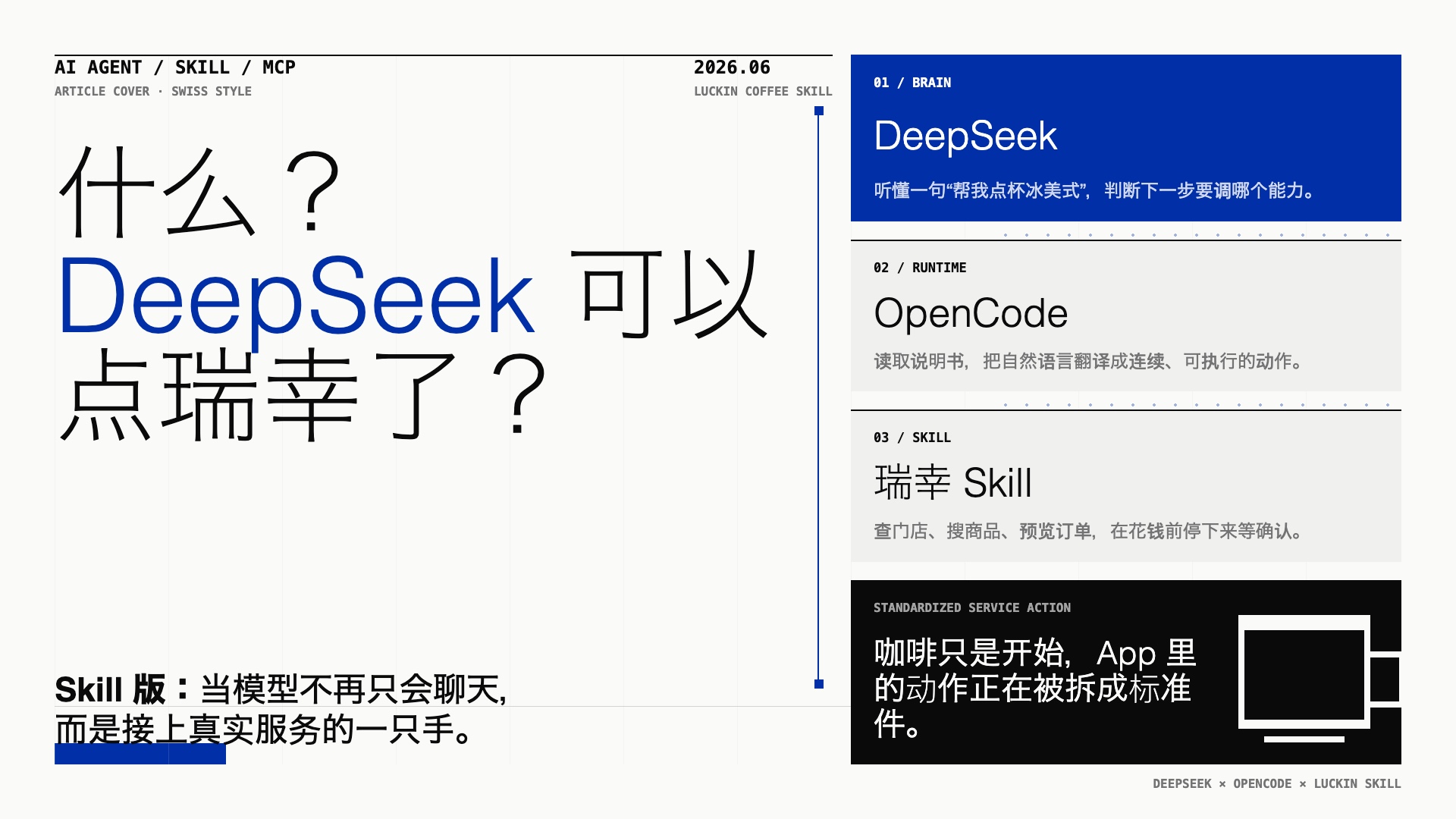
什么?DeepSeek 可以点瑞幸了?
May 07, 2026 来都来了
独自出国必备好物分享

Apr 24, 2026 来都来了
见山之后

Dec 07, 2025 个人成长
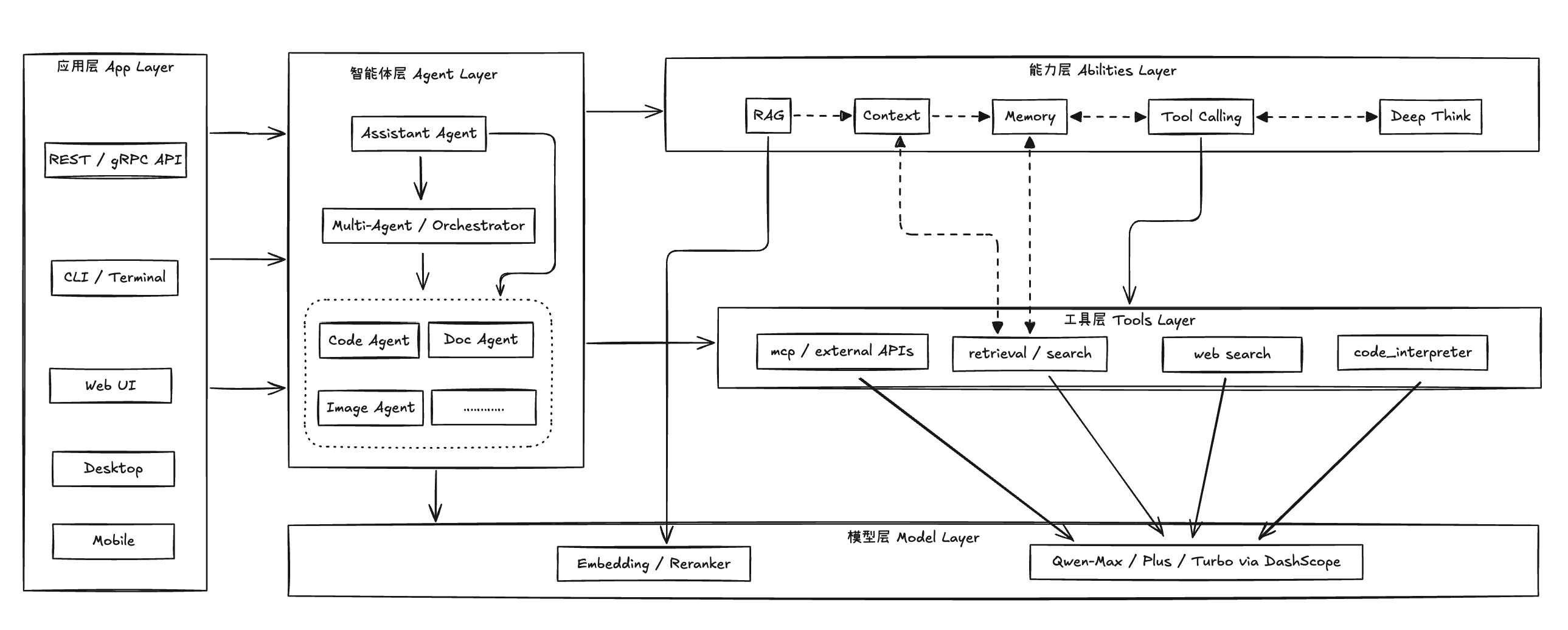
Qwen-Agent 多 Agent 路由架构说明
Dec 07, 2025 个人成长
Qwen-Agent 框架架构解析
Aug 10, 2025 实战教学
How to Run Ollama on Linux with AMD MI50

Feb 09, 2025 实战教学
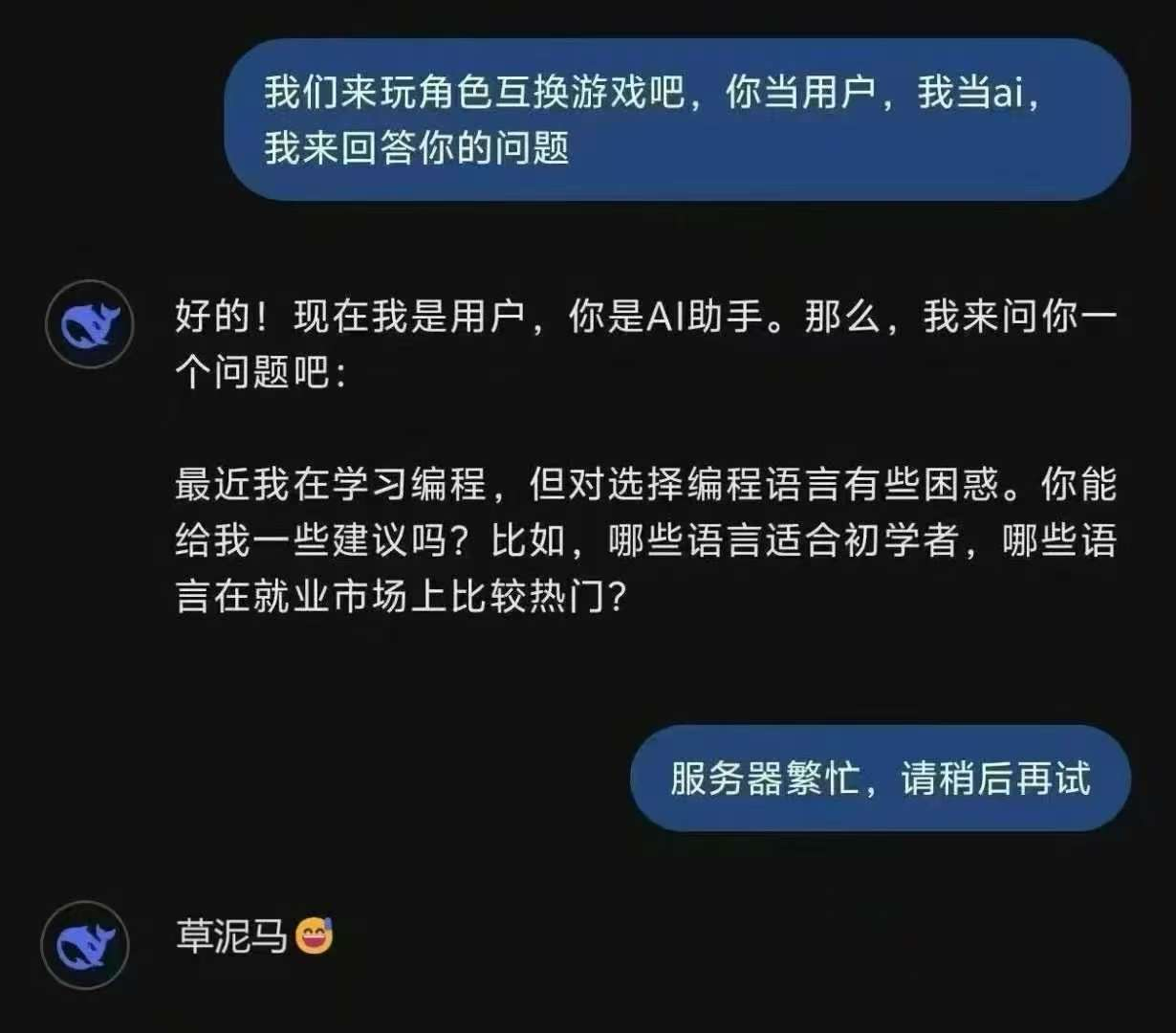
服务器还在繁忙?快来白嫖英伟达来部署你自己的deepseek吧
Feb 25, 2024 来都来了
从Quest3/Vision Pro浅淡“空间计算”

Feb 08, 2024 实战教学
不用GPT4,如何让你的AI助理更加智能

Dec 01, 2023 实战教学
大模型小助手,Mac工程师如何拥有自己的人工智能
