
小伙伴们新年好啊,颓废的 2023 年总算是过去了,过去这一年因为自己的状态不太好,一直也没怎么更新,2024 年是时候重新拾起行囊再出发啦!
前言
去年年底我写过一篇《大模型小助手,Mac 工程师如何拥有自己的人工智能》,在那篇文章里我介绍了如何利用自己手头的计算资源(Mac 电脑)快速拥有一个人工智能助手,然而大多数人手头的算力是很孱弱的,以至于大家千方百计搭桥建梯想要拿到 OpenAI 这艘大船的船票。这无可厚非,但我们知道,在我们这个伟大的国家,科技一定是要讲究自主研发的,不然谈何遥遥领先。因此在去年 8 月,随着《生成式人工智能服务管理暂行办法》的正式实施, 中国自人己的生成式人工智能之路,终于从政策上给出了要求和肯定,让 AIGC 行业发展不再迷茫。
现如今经历了一年多的发展,国产 AI 已经慢慢地走向成熟,其智能体的效果已经具备了产业应用场景落地的基本条件。因此今天我准备从自己的实际需求入手,抛弃 OpenAI,使用我们国内的 AI 平台,展示一下如何使用 LlamaIndex 框架和智谱 AI 结合起来处理常见的应用场景——知识库检索。
大炼钢铁——国产大模型间的军备竞赛
ChatGPT 及其背后的 GPT4 大火之后,国内迅速刮起一阵自主研发大模型的风,先不管开源与否,目前市面上叫得上名号的就不止以下这些(排名不分先后):
| 机构/公司 | 模型名称 |
|---|---|
| 百度 | 文心大模型 |
| 抖音 | 云雀大模型 |
| 智谱 | GLM 大模型 |
| 中国科学院 | 紫东太初大模型 |
| 百川智能 | 百川大模型 |
| 商汤 | 日日新大模型 |
| MiniMax | ABAB 大模型 |
| 上海人工智能实验室 | 书生通用大模型 |
| 科大讯飞 | 星火认知大模型 |
| 腾讯 | 混元大模型 |
| 阿里巴巴 | 通义千问大模型 |
吕布之后,人人皆有吕布之勇。 国产大模型亦是如此,GPT4 与大国政策双向奔赴后,这些 AI 厂商都想在国内大模型这场军备竞赛中占得一席之地。
这些 AI 厂商一般有三种提供服务的方式:
- 模型私有部署:直接部署开源或者闭源的模型(需要显卡);
- AI 开发平台:很多平台提供了 LLM 服务,可以在线进行模型测试、开发、部署、微调等服务(直接付费即可);
- API 调用:这个就和 OpenAI 早期的服务模式一样,提供 API 的调用。
在上一篇文章中,我们选择了清华大学与智谱合作开发且开源的 ChatGLM3 作为私有化部署的模型。鉴于对其开源产品的丰富产品线以及较好的使用体验,这次我们仍然选择智谱 AI 作为本文的大模型底座。
2024 年 1 月 16 日,智谱 AI 发布了他们最新的大模型 ChatGLM4,性能全面比肩 GPT-4(乐观计算能达到 GPT-4 九成以上),并且在中文能力上超过了所有竞争对手,长文本能力也一骑绝尘。笔者体验下来效果非常好,初学者可以上手体验。
智谱 AI
智谱 AI 是基于清华大学 ChatGLM 系列大模型衍生出的 AI 产品,今天我们主要通过他的开放平台赋能 👉https://open.bigmodel.cn/

进入开发工作台后,我们可以可以看到最新的 GLM-4 模型已经可供使用了,适用于复杂的对话交互和深度内容创作设计场景,今天我们主要用的也是这个模型。点击右上角,我们需要查看自己的 API key,新用户给了一个月 300 万额度的体验 token,基本够用了。
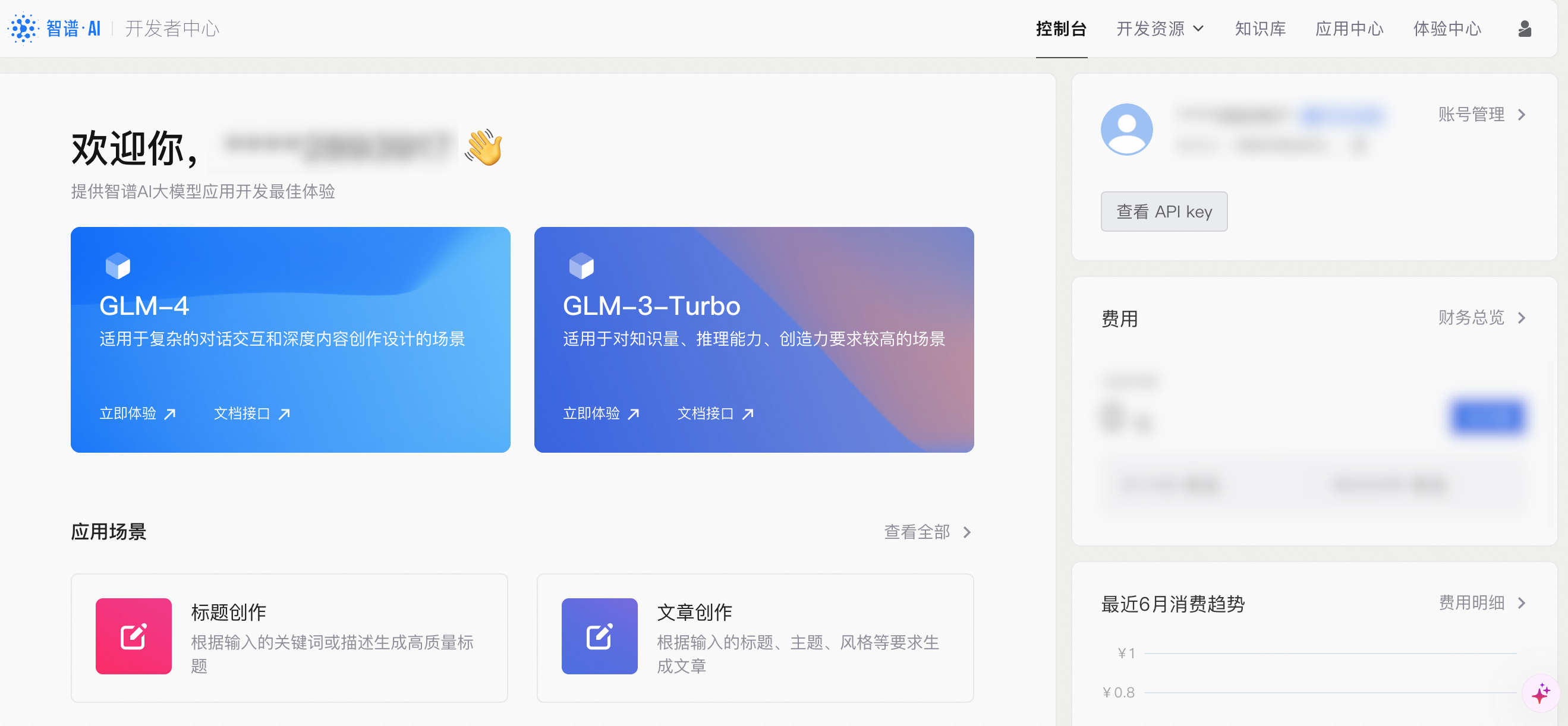
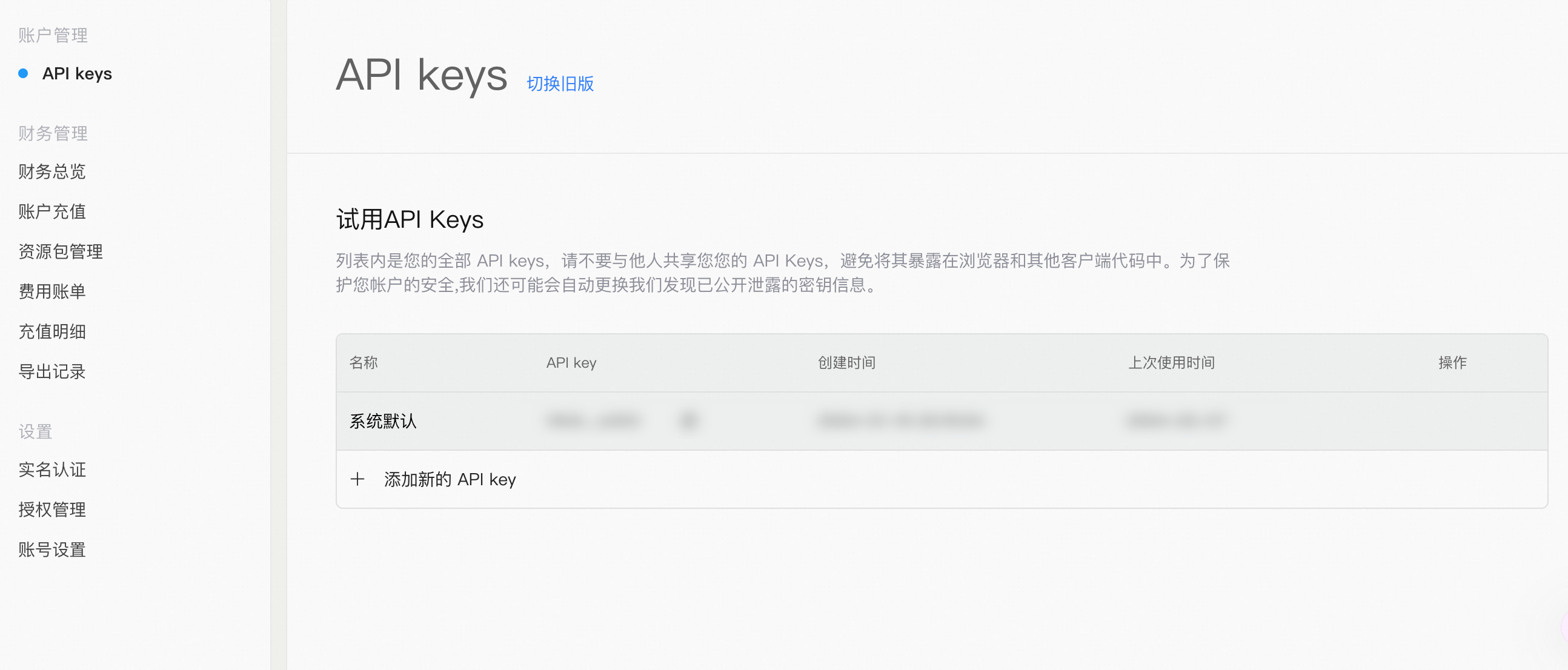
点击「查看 API Key」 可以看到默认的 API Key,直接拷贝使用,或者创建新的 API Key,这个 key 我们后面会用到。
API 的基本使用
这块的使用参考开发者后台里的接口文档,基本能了解个七七八八,这里就简单给一个使用的 demo 了。接口文档地址 👉https://open.bigmodel.cn/dev/api
首先安装 zhipuai:
pip install zhipuai
目前 zhipuai 的版本已经到了 2.0.1,和去年发布的 1.0.7 在 api 使用上是有一些差异的,需要关注一下。
写一个测试的例子:
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="") # 填写您自己的APIKey
response = client.chat.completions.create(
model="glm-4", # 填写需要调用的模型名称
messages=[
{"role": "user", "content": "作为一名营销专家,请为我的产品创作一个吸引人的slogan"},
{"role": "assistant", "content": "当然,为了创作一个吸引人的slogan,请告诉我一些关于您产品的信息"},
{"role": "user", "content": "智谱AI开放平台"},
{"role": "assistant", "content": "智启未来,谱绘无限一智谱AI,让创新触手可及!"},
{"role": "user", "content": "创造一个更精准、吸引人的slogan"}
],
)
print(response.choices[0].message)
上面代码我们注意到,messages 参数是一个数组,其设计是天然针对对话、以及少样本提示的。
比如:
messages = [
{"role": "user", "content": '提问1'},
{"role": "assistant", "content": '回答1'},
{"role": "user", "content": '提问2'},
{"role": "assistant", "content": '回答2'},
{"role": "user", "content": prompt},
]
AI 会跟去前面的对话历史,对最后的 messages 进行回答。
🤖:少样本提示(Few-shot prompting)是人工智能领域中的一个概念,特别是在自然语言处理(NLP)和机器学习模型训练中。所谓的“少样本”指的是在模型训练过程中,使用非常有限的数据样本对模型进行训练。这种方法要求模型能够从少量数据中快速学习和泛化,以便在新颖或未见过的数据上进行准确的预测。
知识库检索
大语言模型在专业领域回答缺乏依据、存在幻觉已经是一种共识,因此,为了在私域知识问答方面弥补通用大语言模型的一些短板,通常有两种解决方案:
- 微调(fine-tune):利用私有知识库对对 LLM 模型进行附加训练,以增加额外的知识
- 上下文学习( in-context learning):在 LLM 查询提示中添加一些额外的知识
据观察,目前由于上下文学习比微调更简单,所以上下文学习比微调更受欢迎,在这篇论文中讲述了这一现象:https://arxiv.org/abs/2305.16938。
对于上下文学习,我们通常采取的方案是将私域知识文档进行切片然后向量化,后续通过向量检索进行召回,再作为上下文输入到大语言模型进行归纳总结。
例如,要构建一个可以回答关于某个人的任何问题,甚至扮演一个人的数字化化身的应用程序,我们可以将上下文学习应用于一本自传书籍和 LLM。在实践中,应用程序将使用用户的问题和从书中"搜索"到的一些信息构建提示,然后查询 LLM 来获取答案。
在这种搜索方法中,实现从文档/知识(上述示例中的那本书)中获取与特定任务相关信息的最有效方式之一是嵌入(Embedding)。
嵌入(Embedding)通常指的是将现实世界的事物映射到多维空间中的向量的方法。例如,我们可以将图像映射到一个(64 x 64)维度的空间中,如果映射足够好,两个图像之间的距离可以反映它们的相似性。
而 LlamaIndex 就是目前使用较多的工具之一。LlamaIndex 是一个开源工具包,它能帮助我们以最佳实践去做 in-context learning:
- 它提供了各种数据加载器,以统一格式序列化文档/知识,例如 PDF、维基百科、Notion、Twitter 等等,这样我们可以无需自行处理预处理、将数据分割为片段等操作。
- 它还可以帮助我们创建嵌入(以及其他形式的索引),并以一行代码的方式在内存中或向量数据库中存储嵌入。
- 它内置了提示和其他工程实现,因此我们无需从头开始创建和研究,例如,《用 4 行代码在现有数据上创建一个聊天机器人》。
感兴趣的朋友可以去查看 LlmaIndex 官网 👉 https://docs.llamaindex.ai/en/stable/ 去了解更多信息。

LlamaIndex
先用 Pip 简单安装一下 LlamaIndex:
pip install llama-index
然后我们导入下测试是否安装成功:
import llama_index
print(llama_index.__version__)
# 0.9.10
接下来让 LlamaIndex 使用 智谱 AI 作为大模型底座来实现基于知识库的问答。
LlamaIndex 是一个开源的,并且在海外十分流行的 in-context learning 工具,因此支持众多目前火热的大模型,只是很不凑巧,并没有 「智谱 AI」 以及国内的一众 AI 产品,任重道远啊。
好在,LlamaIndex 提供了非常灵活的接口,支持我们自定义一个可以集成的大模型 👉Customizing LLMs within LlamaIndex Abstractions
集成智谱 LLM
LlamaIndex 提供了一个叫做 CustomLLM 的抽象类来让我们方便的集成自己的大模型产品,只需要负责将文本传递给模型并返回新生成的标记即可。通过这种方式,我们可以结合一些本地模型(例如之前提到的 ChatGLM3),或者是一个 API 的包装器,当然了,如果为了获取完全私人隐私的大模型体验,肯定是本地模型优先。本文为了获得更高效的体验,直接集成智谱 AI 的 API 即可。
参考文档,我们只需要实现 metadata、complete 以及 stream_complete 三个重要方法即可,熟悉 OpenAI API 的朋友想必一眼就看出来这三个是什么东西了。我们只需要参考智谱 AI 的文档依次实现即可。这里方便起见,就不实现 stream_complete 的方法,智谱 AI 官网有例子,参考即可。下面是一个简单的 demo👇
def invoke_prompt(prompt):
response = client.chat.completions.create(
model="glm-4",
messages=[
{"role": "user", "content": prompt},
],
top_p=0.7,
temperature=0.9
)
return str(response.choices[0].message.content)
class ZhiPuLLM(CustomLLM):
model_name: str = "glm-4"
@property
def metadata(self) -> LLMMetadata:
"""Get LLM metadata."""
return LLMMetadata(
model_name=self.model_name,
)
@llm_completion_callback()
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
response = invoke_prompt(prompt)
return CompletionResponse(text=response)
集成智谱 AI 文本嵌入 Embedding
智谱 AI 也提供了文本嵌入接口,那我们当然也是直接拿来用了,这样子就彻底摆脱了了 OpenAI 和自己搭建模型了。
LlamaIndex 的嵌入式基于 BaseEmbedding 实现的,参考官网的文档(Custom Embeddings Implementation),我们也写一个 智谱 AI 的实现,直接看代码:
def invoke_embedding(query):
response = client.embeddings.create(
model="embedding-2", # 填写需要调用的模型名称
input=query,
)
return response.data[0].embedding
class ZhiPuEmbedding(BaseEmbedding):
_model: str = PrivateAttr()
_instruction: str = PrivateAttr()
def __init__(
self,
instructor_model_name: str = "text_embedding",
instruction: str = "Represent a document for semantic search:",
**kwargs: Any,
) -> None:
# self._model = 'text_embedding'
# self._instruction = instruction
super().__init__(**kwargs)
@classmethod
def class_name(cls) -> str:
return "zhipu_embeddings"
async def _aget_query_embedding(self, query: str) -> List[float]:
return self._get_query_embedding(query)
async def _aget_text_embedding(self, text: str) -> List[float]:
return self._get_text_embedding(text)
def _get_query_embedding(self, query: str) -> List[float]:
embeddings = invoke_embedding(query)
return embeddings
def _get_text_embedding(self, text: str) -> List[float]:
embeddings = invoke_embedding(text)
return embeddings
def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]:
return [self._get_text_embedding(text) for text in texts]
知识库检索,启动!
万事俱备,只欠东风。前菜都已准备完毕,剩下的就是将前面的整合在一起,让我们看看能不能正常运行吧!
首先先准备一个你要做 Embedding 的知识库,我这里直接用了我的体检报告。
# define our LLM
llm = ZhiPuLLM()
embed_model = ZhiPuEmbedding()
service_context = ServiceContext.from_defaults(
llm=llm, embed_model=embed_model
)
# Load the your data
loader = CJKPDFReader()
documents = loader.load_data(file=self.file_path)
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
# Query and print response
query_engine = index.as_query_engine()
response = query_engine.query("在这份体检报告里,我的血常规检测有什么问题吗?")
print(response)
这里我们使用了 LlamaIndex 内置的 PDF 解析器,将文件转换成所需的向量 index,直接调用 query_engine.query() 函数查询即可。至此,一个简易的基于知识库检索的大模型案例便完成了。
通常情况下,我们会不断的对整个文档进行知识检索,因此有必要将我们构建的索引持久化,这样下次再次提问的时候就可以不用重新 Embedding(当然也可节省 token)。持久化也很简单,我们只需要调用 index.storage_context.persist(persist_dir=PERSIST_DIR) 函数即可,等下次再使用的时候,可以先从持久化的索引文件中 load,同样很容易,执行以下函数即可:
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
我们来看看返回的结果,是不是还可以呢?

结语
以上便是本文的全部内容了,本文主要介绍了如何使用 LlamaIndex 结合大模型落地一个知识库索引,主要就是自定义 LLM 和自定义 Embedding 这两块。这两个点对接之后,余下的各种玩法也几乎和使用 OpenAI 无异。如果你对大模型感兴趣的,并且想了解更多可以落地的 AI 玩法的话,不妨给我点个赞关注一下,后面再和大家分享。