
前言
历史的车轮滚滚向前,大模型的发展让 AI 离每个人都更近了一步。今年 3 月的时候简单聊了一下 AIGC,现如今半年多过去了,ChatGPT 依旧大放异彩。无论是百度的文心一言还是阿里的通义千问,在 GPTs 面前都变成了拙劣的模仿。

现如今每隔几天就有新鲜的技术出炉,让人目不暇接,同时具备可玩性和想象空间的各种应用和开源库,仿佛让自己回到了第一次设置 JAVA_HOME 的日子,于是我便蹦出了一个对自己的工作和生活可能有帮助的想法——“拥有自己的人工智能”。
目标是搭建出一个不依赖云端服务,可以在本地运行,且效果可以接受的类 ChatGPT 服务。为什么要在本地搭建而不是直接采用现成的云服务呢?从数据安全的角度看,一些数据还是不太方便随意上传至云端的,而且云端的问题回答也会经过各个服务商审核,不可避免的会出现降智的情况。另一方面,这些在线的云服务成本较高,chatGPT plus 每个月 20 美元,还要熟练掌握各种上网技巧,虽然能力很强大,但是再没有一个完美的变现渠道的情况下,对于我的荷包来说还是有很大负担。最后对于一个工程师来说,能自己搭建一个完整的方案,使用一个自己调教出来的 AI,也是出于对技术探索的本能使然。
方案概述
由于是在本地运行的,选择一个好的设备则是第一步要考虑的事情了。笔者家中刚好有一台 2020 年 M1 芯片的 Mac Mini,一直作为家里的 homelab 长期运行。除了平时在家里用他编译代码、还会用它来设置苹果的内容缓存,提高局域网内苹果服务的连通性。如今廉颇尚未老矣,还是可以再战 AI 的。
由于 M1 芯片的统一内存架构和开源社区对 Apple 芯片在 AI 方面的支持, 如今用它作为一个本地运行大模型的载体再合适不过了。
我的方案如下图所示 👇。

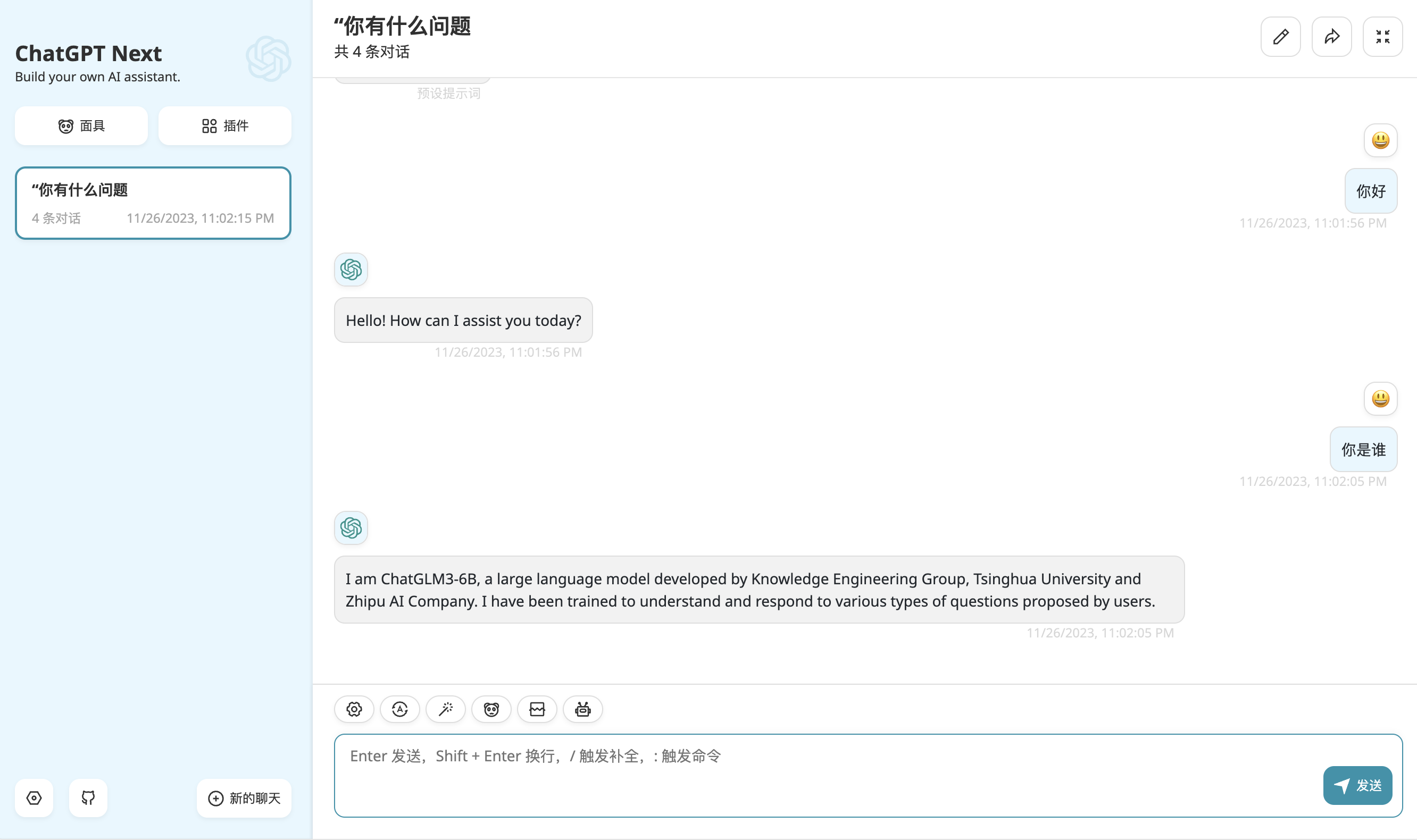
在这套方案中,我采用实力排上游、并且在使用上对学术和商业都友好的国产大模型 ChatGLM3-6B 对话模型,同时使用 chatglm.cpp 对 ChatGLM3-6B 进行量化加速以及 API 协议的兼容;通过 Cloudflare 的 Tunnels 将运行在家中 HomeLab 的 service 映射至公网;使用 ChatGPT Next Web 作为 UI 层并通过 Vercel 托管网页(当然这里也可以选择下载 ChatGPT Next Web 的 desktop App 直接使用)。最后的效果如下图所示。
详细步骤
模型准备
这个环节我们的主要任务是把模型文件准备好、完成量化,并通过命令行的方式,进行交互式对话验证。
下载对话语言模型 ChatGLM3-6B
为什么选择 ChatGLM3-6B?
因为综合比对下来,ChatGLM3-6B 是我这台 Mac Mini(M1+16G)能带得动的且效果还算可以的开源大模型了 🤷♂️

尽管 ChatGLM3-6B 已经开源,HuggingFace 可以直接下载,但是鉴于国内的网络环境,这里还是推荐使用阿里的 ModelScope,亲测下载速度能翻很多倍。
// 从 Git 仓库下载模型文件
// HuggingFace
git lfs install
git clone https://huggingface.co/THUDM/chatglm3-6b
// ModelScope
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
🤖 ChatGLM3-6B:
git lfs是一个用于在 Git 仓库中管理大型文件系统的工具。它允许您将本地文件系统上的文件或目录挂载到 Git 仓库中,从而使您可以像操作普通文件一样操作这些大型文件。这可以提高协作开发的可行性,因为多个开发人员可以同时访问同一文件系统中的文件,而无需通过网络进行协作。
使用 chatglm.cpp 对 ChatGLM3-6B 进行量化加速
chatglm.cpp 的出现拯救了纯 MacBook 党,让我们能在(低性能的)果本上基于 CPU 进行推理,也不会损失过多的精度。(其实损失多少我也不知道,不影响我们正常进行工程部署验证就行)
用以下命令将代码下载到本地,Github Repo: https://github.com/li-plus/chatglm.cpp
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp
由于使用到了 git 的 submodule 功能,如果一开始你只是 git clone 命令而忘记了加--recursive参数,后期你还可以通过在chatglm.cpp文件夹中执行以下命令拉取相关代码
git submodule update --init --recursive
安装依赖:
python3 -m pip install -U pip
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece
值得一提的是,针对 Apple silicon GPUs,PyTorch 使用新的 Metal Performance Shaders(MPS)后端进行 GPU 训练加速。这个 MPS 后端扩展了 PyTorch 框架,提供了在 Mac 上设置和运行操作的脚本和功能。MPS 框架通过针对每个 Metal GPU 家族独特特性的微调内核来优化计算性能。详情可参考 👉Accelerated PyTorch training on Mac
而我们要做的就是只需要安装 torch 的每夜版(Nightly),感谢开源 🙏
conda install pytorch torchvision torchaudio -c pytorch-nightly
随后使用 convert.py 对 ChatGLM-6B 进行 8-bit 量化处理即可:
python3 chatglm_cpp/convert.py -i THUDM/chatglm-6b -t q8_0 -o chatglm-ggml-q8.bin
如果电脑带不动,还可以尝试 4-bit、5-bit 参数量化,完整的参数列表如下:

编译&运行
利用 Cmake 编译整个项目:
cmake -B build
cmake --build build -j --config Release
同样的,对于 M 系列芯片的苹果电脑只要设置了-DGGML_METAL=ON也是可以加速的,命令如下 👇
cmake -B build -DGGML_METAL=ON && cmake --build build -j
在安装的过程中可能会发生 No module named 'chatglm_cpp._C'的错误,解决方法有两个
- 执行
python setup.py build_ext --inplace命令 - 把编译出来的文件
_C.cpython-311-darwin.so放到chatglm_cpp目录下。
验证模型问答效果
完成模型量化后,就可以在本地把大模型跑起来了,命令如下:
./build/bin/main -m chatglm3-ggml-q8.bin -i

搭建模型 API 服务
在托管我们的 API 之前,需要先搭建使用模型的 API,chatglm.cpp已经很贴心的为我们支持了两种 API 搭建方式,用于快速提供后端服务,在使用两种搭建方式前,我们需要先安装相关的依赖:
pip install 'chatglm-cpp[api]'
Chatglm.cpp支持两种 API 的构建方式,分别是
- LangChain API
- OpenAI API
// 适配LangChain API的HTTP Server
MODEL=./chatglm3-ggml.bin uvicorn chatglm_cpp.langchain_api:app --host 127.0.0.1 --port 8000
// 适配OpenAI API的HTTP Server
MODEL=./chatglm3-ggml.bin uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000
使用起来也是十分的简单,当然也可以选择使用 docker 部署相应的服务,这里就不多说了,可以参考https://github.com/li-plus/chatglm.cpp#using-docker
LangChain是一个开源的框架,它可以让 AI 开发人员把像 GPT-4 这样的大型语言模型(LLM)和外部数据结合起来。简单来说,它可以让你的 LLM 在回答问题时参考整个数据库。所以你现在可以让你的 GPT 模型访问最新的数据,比如报告、文档和网站信息。
出门右转 ➡️ LangChain 中文网
我们可以通过 curl 命令来测试一下我们的 API
// 通过 curl 测试 LangChain 的 API
curl http://127.0.0.1:8000 -H 'Content-Type: application/json' -d '{"prompt": "你好"}'
// 通过 curl 测试适配 OpenAI API
curl http://127.0.0.1:8000/v1/chat/completions -H 'Content-Type: application/json' \
-d '{"messages": [{"role": "user", "content": "你好"}]}'
笔者这里选择了适配 OpenAI API 的方式,主要考虑是现在市面上适配 ChatGPT 的第三方应用非常多,大多都提供设置 openai api 的代理地址,选择这种方式的好处是,一旦我们选择了第三方应用,我们要做的便只是换一个代理地址即可。
API 托管
现在我们已经有了一个可用的 api 服务地址了 👉 http://127.0.0.1:8000/v1/chat/completions,我们知道这个地址只能在本地电脑上启用,哪怕用自己电脑的 IP 也只能在局域网内使用,显然这并不满足我们的诉求,因此,我们需要将自己的服务映射到公网供自己远程访问,即内网穿透。
🤖 ChatGLM3-6B:内网穿透,顾名思义,是指在内部网络(内网)中实现穿透外网(公网)的通信。通常情况下,内网是指一个组织(如公司、政府部门等)的专用网络,而外网则是指互联网,两者之间通过防火墙等安全设备进行严格控制。内网穿透技术可以帮助位于内网的用户和设备与外网进行通信,实现内外网之间的数据交换。
内网穿透技术主要有以下几种:
代理服务器:通过在内网设置代理服务器,将内网中的设备与外网建立连接。数据在传输过程中会经过代理服务器,从而实现内外网之间的通信。
虚拟专用网络(VPN):通过建立一个加密的隧道,将内网中的设备与外网连接。数据在传输过程中具有较高的安全性,同时也能实现内外网之间的通信。
端口映射:将内网中的某个端口映射到外网的端口,实现内外网之间的通信。这种方法简单易用,但安全性较低。
代理服务器和 VPN 的结合:同时使用代理服务器和 VPN 技术,将内网中的设备与外网连接。这种方法既保证了通信的安全性,又实现了通信的效率。
内网穿透技术在许多场景下非常有用,例如远程访问、远程调试、远程协作等。但在实际应用中,内网穿透技术也存在一定的风险,如网络安全、信息泄露等。因此,使用内网穿透技术时,需要注意加强网络安全防护。
目前市面上内网穿透的方案已经有很多了,可以通过在购买的云服务厂商的机器上使用 frp 搭建,也可以使用现成的诸如花生壳这样的第三方付费服务搭建,这里我选择使用 CloudFlare Tunnel 将服务托管出去。
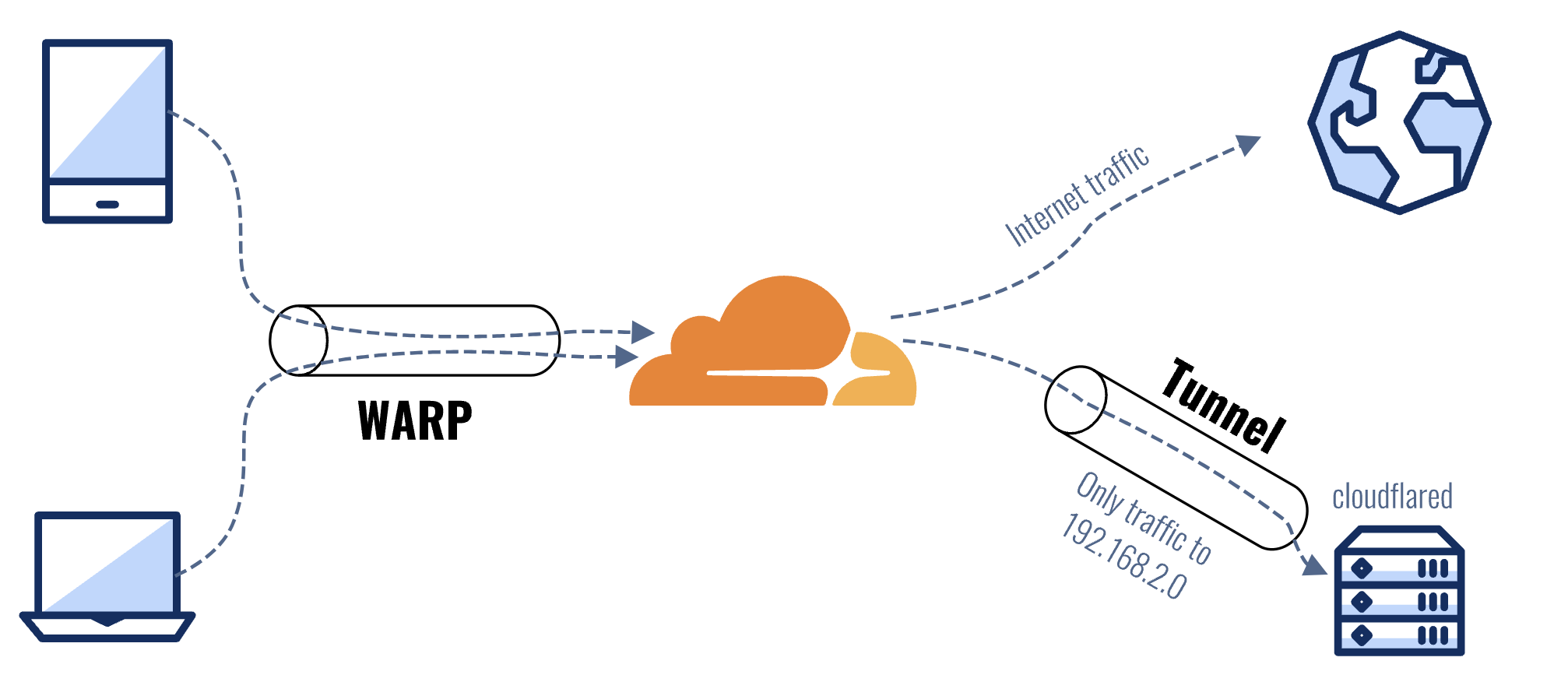
之所以选择 Tunnel,主要是因为:
- 相比 NPS 之类传统穿透服务,Tunnel 不需要公网云服务器,同时自带域名解析,无需 DDNS 和公网 IP。
- 将非常规端口服务转发到 80/443 常规端口。 无论是使用公网 IP + DDNS 还是传统内网穿透服务,都免不了使用非常规端口进行访问,如果某些服务使用了复杂的重定向可能会导致 URL 中端口号丢失而引起不可控的问题,同时也不够优雅。
- 自动为你的域名提供 HTTPS 认证。
- 为你的服务提供额外保护认证。
- 最重要的是——免费。
Tunnel 的实现原理:Tunnel 通过在本地网络运行的一个 Cloudflare 守护程序,与 Cloudflare 云端通信,将云端请求数据转发到本地网络的 IP + 端口。
互联网上关于 Tunnel 实现内网穿透的文章有很多,推荐一个教程 👉 CloudFlare Tunnel 免费内网穿透的简明教程
客户端选择
自从 ChatGPT 火了以后,网络上各种第三方 webui 应运而生,各种第三方客户端在 GitHub 上盛行,本质上就是一个套壳,其实东西都是差不多的,无非就是看谁支持的特性快一些,多一些罢了。

笔者这里选择了更适合中国宝宝体质的ChatGPT-Next-Web,可以一键拥有自己的跨平台 ChatGPT 应用(Web / PWA / Linux / Win / MacOS)
我们要做也很简单,如下图所示,只需要几那个接口地址改成我们在上一步内网穿透的地址即可。

最后
本文主要介绍了如何在 M1 芯片的 Mac mini 上搭建一个 AI 助手,同样的方法也使用性能差一些的 Macbook Air,考虑到 iPad 使用和 Mac 同源的芯片,不排除未来可以在 iPad 上使用本地计算资源的 AI 助手,后期我也将会分享一些基于 chatglm 配套的玩法,例如给 chatglm 加上自己的知识库,用自己的语音包让 chatglm 说话等等。
笔者认为,AI 也许不会取代人类,但是会使用 AI 的人一定会取代不会使用 AI 的人,如果你觉得 ChatGPT Plus 太贵,不妨参考这个教程去搭建一个你自己的小助手吧!