
引言 软件工程领域的设计模式,就像是建筑师手中的设计蓝图,它们是经验的总结,指导开发者如何在面对层出不穷的编程难题时,构建出既稳固又灵活的软件结构。就像一座经过精心设计的大厦能够经受住风雨的考验一样,一个利用了恰当设计模式的软件系统也能在快速变化的技术世界中稳定运行。它们是从无数成功(和失败)的项目中提炼出来的知识精华,为软件开发者提供了一套通用的、可复用的解决方案框架。
这些模式不仅仅是静态的原则或者是一成不变的规则,它们更像是一种语言,让开发者之间能够有共同的理解和沟通基础。在这个基础上,设计模式允许团队成员更高效地协作,对现有问题提出经过验证的解决方案,同时也能够预见和规避潜在的设计陷阱。通过实施这些模式,开发者能够减少冗余,提升系统的模块化,从而使得代码更加清晰、扩展性更强,同时也更容易被后来者理解和维护。
在本文中,我们将探索设计模式的分类,它们在软件开发中的应用,并深入讨论在特定情境下选择和实施这些模式的最佳实践。通过具体的例子和场景分析,我们能够更好地理解设计模式在现代软件工程中的作用,以及如何运用这些模式来构建出既强大又优雅的代码结构。
设计模式的分类及应用 在软件工程的广阔舞台上,设计模式被分为三个主要类别,每个类别都解决一系列特定的问题,它们如同不同类型的工具,针对特定的工作选择合适的工具至关重要。
创建型模式,例如**单例和工厂方法**,主要关注对象的创建机制,以确保对于一个特定类而言,系统中只存在一个实例,或者将对象的创建和使用解耦,以增强系统的灵活性和可扩展性。在实际应用中,当我们需要控制客户如何创建一个对象,或者当我们知道对象的创建过程需要大量配置时,这些模式就显得尤为重要。例如,一个复杂的游戏中的资源管理器可能就会采用单例模式来确保所有的游戏组件都能够访问全局的、唯一的资源实例。
结构型模式,如**适配器和代理模式**,帮助设计系统中各个部件之间的组织方式,确保当系统的一部分发生变化时,不会影响到整个系统的功能。它们通过确保每个部分都能够独立地工作,来提高系统的整体灵活性。比如,在一个视频流服务中,适配器模式可以用来确保新的视频编码格式能够被现有的播放器支持,而不必对播放器进行大规模的重写。
行为型模式,例如**观察者和策略模式**,主要关注对象之间的交互和职责分配。这些模式不仅帮助定义对象间的通信模式,而且也使得系统更易于理解和扩展。观察者模式允许对象在无需知道其他对象具体实现的情况下,依旧能够相互通信,这在构建用户界面组件时尤其有用,其中一个动作可能需要更新多个界面元素。
通过深入分析这些模式,我们能够更好地理解它们在软件开发中的价值,以及如何将这些理论应用到实际开发的项目中。这不仅仅是一个理论上的练习;通过具体的代码示例和场景分析,我们将展示这些模式如何帮助开发团队构建更健壮、更可维护、更高效的软件系统。
设计模式的好处与挑战 设计模式的引入往往能够带来显著的好处。首先,它们提供了一种重用解决方案的方式,这可以节省时间和资源,并减少错误。例如,使用工厂模式可以创建一个集中的创建点,允许开发者轻松调整和维护创建逻辑,而无需遍布代码库的重复代码。同样,装饰器模式允许开发者扩展对象的行为,而无需修改现有类的代码,这是增强功能时尊重开闭原则的典范。
然而,设计模式的使用并非没有挑战。过度使用或不恰当使用设计模式可能会导致系统过于复杂,难以理解和维护。比如,一个简单的问题如果使用了一个复杂的模式来解决,可能会引入不必要的抽象层,从而导致代码的可读性和可维护性降低。因此,软件工程师必须具备判断何时使用设计模式的智慧,并且能够根据项目的具体需求和上下文来选择合适的模式。
此外,设计模式的实施需要团队成员有共同的理解,这意味着必须有一个良好的沟通和文档化过程。团队中的每个成员都需要理解这些模式的目的和实现方式,这样才能确保模式被正确地应用,并且整个团队能够有效地协作。
总结而言,设计模式在软件工程中的应用是一个平衡艺术。它们在提升代码质量、促进团队协作和增强软件的可持续发展方面发挥着关键作用。软件工程师需要不断地学习和实践,以便能够熟练地运用这些模式来解决日常开发中遇到的问题。通过理解设计模式的原理和适用场景,我们可以更加明智地选择何时以及如何使用它们,从而构建出更加健壮和可维护的软件系统。
设计模式的实际案例和代码示例 设计模式不仅在理论上具有吸引力,它们在实际应用中同样展现出巨大价值。例如,考虑一个电子商务平台,其中的购物车功能可以通过“单例模式”实现,以保证每个用户在浏览过程中都有一个且只有一个购物车实例。以下是一个简化的单例模式代码示例,用于创建一个购物车实例:
public class ShoppingCart { private static ShoppingCart instance; private ShoppingCart() { // Private constructor to prevent instantiation. } public static ShoppingCart getInstance() { if (instance == null) { instance = new ShoppingCart(); } return instance; } } // Usage public class Main { public static void main(String[] args) { ShoppingCart cart1 = ShoppingCart.getInstance(); ShoppingCart cart2 = ShoppingCart.getInstance(); System.out.println(cart1 == cart2); // Output: true, cart1 and cart2 refer to the same instance. } } 在这个例子中,ShoppingCart 类确保了全局只有一个实例被创建。使用 getInstance() 方法保证了无论多少次调用构造函数,返回的都是同一个对象实例。
...

“UGC 不存在了”——借鉴自《三体》
ChatGPT 的横空出世将一个全新的概念推上风口——AIGC( AI Generated Content)。
GC 即创作内容(Generated Content),和传统的 UGC、PGC,OGC 不同的是,AIGC 的创作主体由人变成了人工智能。
xGC
PGC:Professionally Generated Content,专业生产内容 UGC:User Generated Content,用户生产内容 OGC:Occupationally Generated Content,品牌生产内容。 AI 可以 Generate 哪些 Content? 作为淘宝内容线的开发,我们每天都在和内容打交道,那么 AI 到底能生成什么内容?
围绕着不同形式的内容生产,AIGC 大致分为以下几个领域:
文本生成 基于 NLP 的文本内容生成根据使用场景可分为非交互式文本生成与交互式文本生成。
非交互式文本生成包括摘要/标题生成、文本风格迁移、文章生成、图像生成文本等。
交互式文本生成主要包括聊天机器人、文本交互游戏等。
【代表性产品或模型】:JasperAI、copy.AI、ChatGPT、Bard、AI dungeon 等。
图像生成 图像生成根据使用场可分为图像编辑修改与图像自主生成。
图像编辑修改可应用于图像超分、图像修复、人脸替换、图像去水印、图像背景去除等。
图像自主生成包括端到端的生成,如真实图像生成卡通图像、参照图像生成绘画图像、真实图像生成素描图像、文本生成图像等。
【代表性产品或模型】:EditGAN,Deepfake,DALL-E、MidJourney、Stable Diffusion,文心一格等。
音频生成 音频生成技术较为成熟,在 C 端产品中也较为常见,如语音克隆,将人声 1 替换为人声 2。还可应用于文本生成特定场景语音,如数字人播报、语音客服等。此外,可基于文本描述、图片内容理解生成场景化音频、乐曲等。
【代表性产品或模型】:DeepMusic、WaveNet、Deep Voice、MusicAutoBot 等。
视频生成 视频生成与图像生成在原理上相似,主要分为视频编辑与视频自主生成。
视频编辑可应用于视频超分(视频画质增强)、视频修复(老电影上色、画质修复)、视频画面剪辑(识别画面内容,自动场景剪辑) 。
视频自主生成可应用于图像生成视频(给定参照图像,生成一段运动视频)、文本生成视频(给定一段描述性文字,生成内容相符视频) 。
【代表性产品或模型】:Deepfake,videoGPT,Gliacloud、Make-A-Video、Imagen video 等。
...
背景 在上一篇文章中,我们介绍了如何设计一个消息中心,传送门 👉《如何设计一个消息中心》
有了承载这些消息的地方后,接下来的问题便是,这些消息从哪里来?
通常对于一个内容型产品来说,在其互动体系中,为了增强消息的用户触达,增强用户的互动心智,在互动(评论、点赞等)行为发生后,会将互动消息推送至消息中心,然后根据不同的互动行为类型匹配不同的消息模版。
然而随着互动行为种类的增加(内容的点赞、评论的点赞……),不断的通过 if…else 来根据不同的消息类型生成不同的消息模版会使得业务代码愈发复杂,难以维护。
不仅如此,一旦需要增加一种新的互动消息时,需要对原有代码进行破坏性修改,违背了“开闭原则”。因此有必要对互动行为消息转发至消息中心这一场景进行抽象,让后续的维护者、建设者只需要关心某一特定的互动行为消息即可(我可不想未来被别人喷在 💩 山上拉 💩)。
策略模式 在说明具体的实现方案前,我们先介绍一个设计模式——策略模式。
策略模式,英文全称是 Strategy Design Pattern。在 GoF 的《设计模式》一书中,它是这样定义的:
Define a family of algorithms, encapsulate each one, and make them interchangeable. Strategy lets the algorithm vary independently from clients that use it.
翻译成中文就是:定义一簇算法类,将每个算法分别封装起来,让它们可以互相替换。策略模式可以使算法的变化独立于使用它们的客户端(这里的客户端代指使用算法的代码)。
策略模式用来解耦策略的定义、创建、使用。实际上,一个完整的策略模式就是由这三个部分组成的。
策略类的定义比较简单,包含一个策略接口和一组实现这个接口的策略类。 策略的创建由工厂类来完成,封装策略创建的细节。 策略模式包含一组策略可选,客户端代码如何选择使用哪个策略,有两种确定方法:编译时静态确定和运行时动态确定。其中,“运行时动态确定”才是策略模式最典型的应用场景。 实现方案 在对策略模式有了基本的了解后,我们尝试在本节将其运用起来。
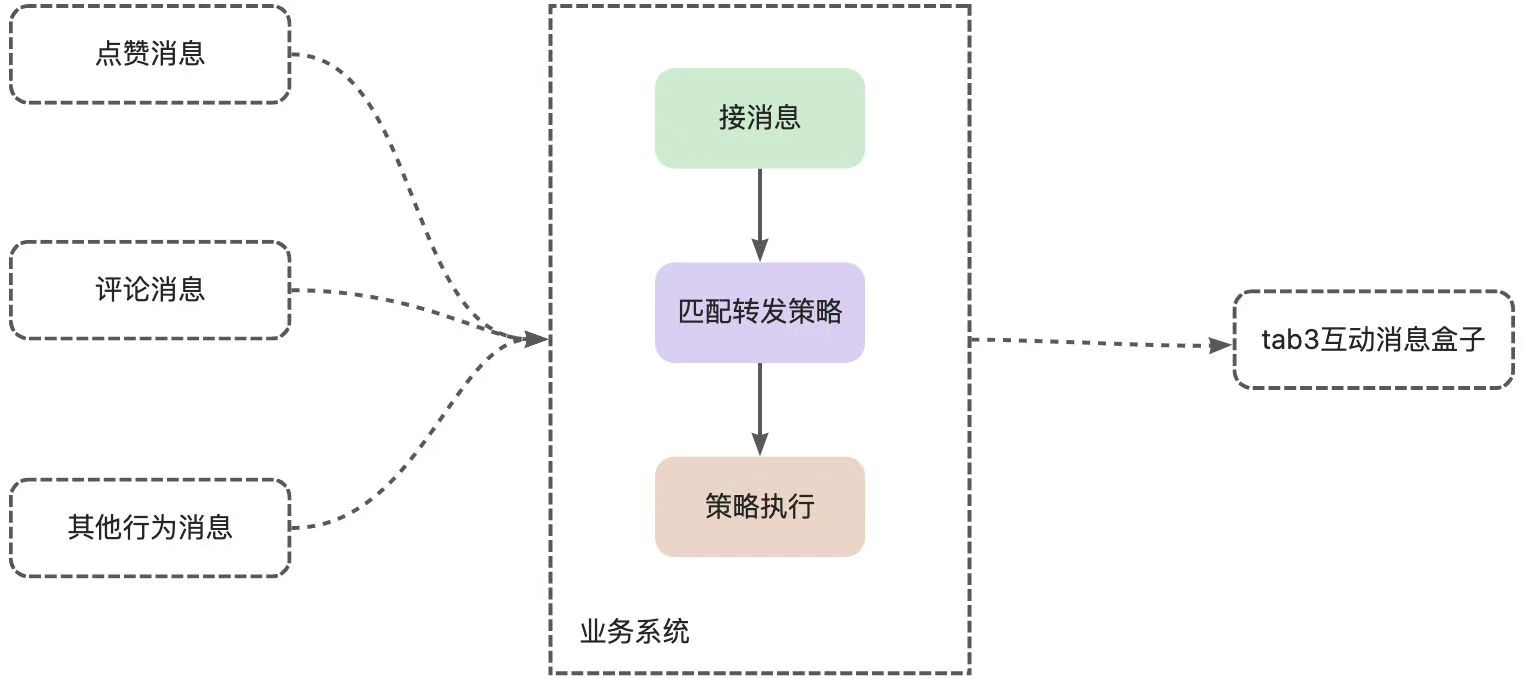
仔细分析了第一章的应用场景后我们发现其实实现链路并不复杂,整体流程如下图所示:
在本例中,根据不同的互动行为类型,我们将点赞消息和评论消息分成以下几类:
点赞类:
内容点赞 评论点赞 评论类:
内容评论 内容评论的回复 转发策略的定义 整个方案中最重要的一环是对转发策略的匹配,因此第一步我们要做的应该是定义一个策略。为了方便后续的扩展(未来可能会有多种转发策略),我们此处定义一个策略接口MsgTransmitStrategy。
public interface MsgTransmitStrategy<T> { // 是否命中策略 boolean match(T message); // 消息类型 TransmitMsgType getMsgType(); // 创建需要转发的消息实体 MessageContent createMessageContent(T message); } 每个策略需要具备的行为能力应该有:
...

从搬运 DTO 到 CRUD 在如今的开发模式下,服务端程序员离原始数据越来越远,和农夫山泉一样,他们不生产数据,他们只是 DTO 的搬运工。从各种 service 中获取数据,再使用 Lambda 进行拆分组装成为了他们的日常工作。
然而,随着各家大厂都开始“降本增效”,DTO 的搬运工越来越不具备竞争力,“技多不压身”变成了下一阶段的 OKR,于是「CRUD 工程师」便“应运而生”了。
本文的内容便是围绕着 CRUD 中的 R(ead)展开的。
数据检索的玄铁剑——索引 在现实生活中,如果你想使用新华字典查询一个字,在没有背下来具体页码的情况下,第一步多半是打开目录,根据拼音首字母快速的锁定目标数据所在的位置范围。如下图 👇
索引究竟是什么? 百度百科是从数据库的角度出发给出了一个索引的定义,维基百科也并没有为 CS 中的索引做一个概述,而是细分了多个领域来介绍 👉https://en.wikipedia.org/wiki/Index
本质上,索引是一种用于提高数据检索效率的技术,它可以是一种复杂的数据结构(Hash,B Tree……),也可以就是一个简单的下标。
为了更好的理解索引,先看一下没有索引的查询是什么样的?
没有索引的查询 上班路上,你和一个长发姐姐擦肩而过,来到公司,惊喜的发现她竟然也在这栋楼上班,此时电梯停在了 3 楼,小姐姐出去之后你便继续乘到了 6 楼,虽然你一直写着代码,但此时你的心早已飞去了三楼。
OK,那么问题来了,如果你想再见到那个长发姐姐,第一想法是什么?一定不是发表白墙吧。
在纠结了半天之后,最后你还是选择了最原始但也是最简单的办法,去三楼的工位一个个找。
你一边遍历着所有工位上的人,一边幻想着等再见面时的场景。终于皇天不负苦心人,在你离她还有六个工位的时候,你见到了她。就在你以为终于能发出“一起喝咖啡”的邀约时,一位靓仔从你的后面“瞬移”到她面前,然后说出了那句“有时间一起喝咖啡吗?”。
事了拂尘去,靓仔最后回头看了你一眼,然后说到:“小伙子,爷有索引”。
微观视角的索引——什么才是有意义的索引 上面这个例子就是一个很典型的场景,在没有索引的情况下,查询就变得简单粗暴——全表扫描。查询耗时完全由数据量决定,海量数据的查询基本无法满足需求。 由于遍历的时间复杂度是 O(n),那么为了让索引变得有意义,其时间复杂度必定是小于 O(n)。
常刷算法题的小伙伴们都知道,经常出现查找的两类数据结构就是数组和树,其实也对应着两种最常见的索引。
哈希索引:复杂度为 O(1) 树索引:复杂度为 O(log n) 哈希索引原理是根据属性组合直接通过哈希函数计算出结果数据的地址,一般来说更快(包括建索引的效率和查询效率),具体性能依赖于数据集和哈希函数的匹配程度。
树索引原理是基于属性组合建立树再根据二分查找定位数据,虽然建索引和查找速度都慢一些,但优势是可以支持范围查询和 front-n 属性匹配(前缀匹配)的查询。其中 front-n 属性的查询意思是,属性组合中的前 1 到前 n 个属性组成的子组合的查找。例如属性组合是 A-B-C,那么树索引可以支持 A、A-B、A-B-C 三个属性组合的查找。
基于这两类数据结构,可以延伸出非常非常多具体类型的索引,这里就不过过阐述了。接下来我们把格局打开,来看看宏观视角下的索引是如何运用的。
宏观视角的索引——全局索引/本地索引 独立于源数据之外,索引的存储自然也是要保存在另一张表中。提供主键查询的表称为主表,满足绝大多数的业务查询场景。提供非主键查询的表称为二级索引表,主表是一级索引表。
...
前言 本文是笔者在团队内部做分享整理的资料的一部分,本次分享主要是站在一个服务端开发的视角对(前端)低代码平台的一些调研,已经剔除了一些敏感数据和信息,可放心食用。
太阳底下无新事 Dreamweaver -> Low-Code 将时钟拨回到 20 年前,那个时候的开发者对于 html/css/js 还处在望而生畏的阶段,Dreamweaver 的出现仿佛让他们看见了曙光。通过简单的拖拽就可以实时预览编排的页面,点击按钮就可以自动生成对应的前端代码,配置好机器信息就可以一键部署访问…… 这些特性让无数开发者趋之若鹜,然后现在他的境况
现如今,Dreamweaver 几乎已经退出了历史舞台,但 Low-Code 似乎又有卷土重来的迹象……
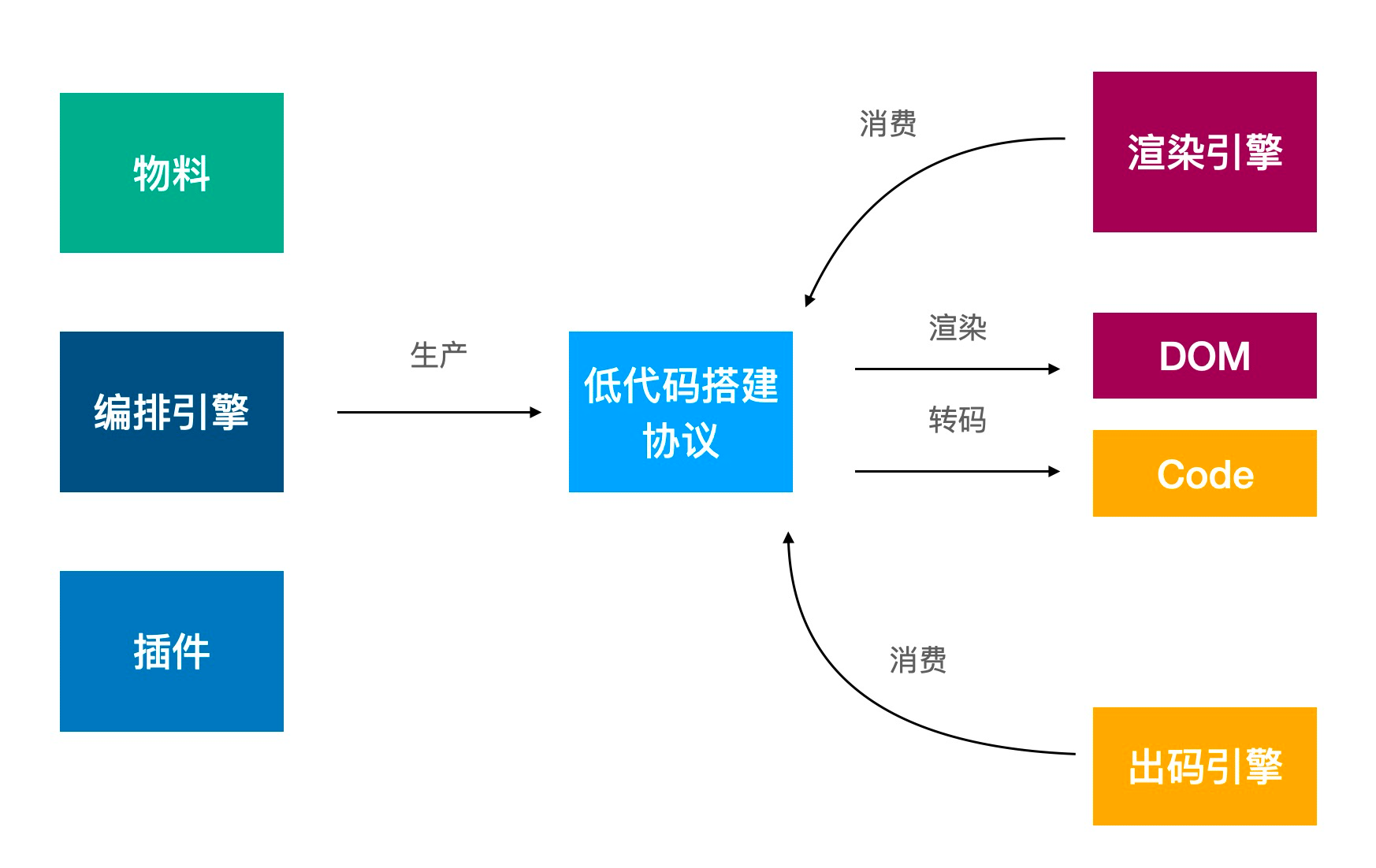
Low-Code 是什么? A low-code development platform (LCDP) is software that provides a development environment used to create application software through graphical user interfaces and configuration instead of traditional hand-coded computer programming.
一句话概括就是 👉 用 GUI+配置取代传统手工编码 技术上,实现低代码平台的关键要素是模型驱动设计、代码自动生成和可视化编程,通过这些手段来隐藏下层的代码细节。
更激进的—— No-Code(零代码) Low-Code 更激进的演进方向是 No-Code,主要的差异点如下:
平台用户:任何业务人员都能使用无代码平台,而低代码平台面向开发者(尽管专业要求不那么高)
核心设计:无代码平台倾向于让用户通过拖拽或简单的表达式来操纵完成应用设计,而低代码平台更倾向于通过人工编码来指定应用程序的核心结构
用户界面:无代码平台为了简化应用设计,一般只支持内置的 UI 库,而低代码平台可能会提供更灵活的 UI 选项,但代价是需要额外编码,使用上的复杂性有所增加
为什么目前低代码只在前端领域很火? 被资源化的前端开发者 工作量大,重复性工作较多,因此生产效率成为了必须要解决的问题。
...

前言 对于一个 Java 开发者来说,Lombok 应该是使用最多的插件之一了,他提供了一系列注解来帮助我们减轻对重复代码的编写,例如实体类中大量的 setter,getter 方法,各种 IO 流等资源的关闭、try…catch…finally 模版等,虽然可以通过 IDE 的快捷帮我们生成这些方法,但这些冗长的代码仍会影响代码的简洁性与可阅读性。 如今,随着使用者数量越来越多,Lombok 甚至成为 IDEA 的内置插件了(2020.3 版本+),可见其影响力。
但不知道使用 Lombok 的你,是否思考过这种自动生成代码究竟是什么原理呢?🤔 这些代码又是怎么产生的呢?而这就是本文要展开介绍的内容了。
Lombok 的安装与使用网络上相关的介绍已经很多了,这里就不多说了,自行查阅相关资料即可。
注解解析的两种方式 关于注解,我在之前的文章里有过详细的介绍,在解释 Lombok 的原理之前,推荐你先阅读 👉《给编译器看的注释——「注解」》 这里主要回顾一下 Lombok 注解的解析方式。
运行时解析 这是最常见的注解解析的方式,运行时能够解析的注解,必须将@Retention设置为RUNTIME,这样就可以通过反射拿到该注解。 例如使用最多的@RequestMapping注解就是一个运行时注解。
@Target({ElementType.TYPE, ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) @Documented @Mapping public @interface RequestMapping { String name() default ""; @AliasFor("path") String[] value() default {}; @AliasFor("value") String[] path() default {}; RequestMethod[] method() default {}; String[] params() default {}; String[] headers() default {}; String[] consumes() default {}; String[] produces() default {}; } 运行时注解的解析原理也很简单,在 java.lang,reflect 反射包中提供了一个接口 AnnotatedElement,该接口定义了获取注解信息的几个方法,Class、Constructor、Field、Method、Package 等都实现了该接口,对反射熟悉的朋友应该都会很熟悉这种解析方式。相关的例子在之前的文章中有介绍过,这里不赘述了。 那 Lombok 的注解也是这种原理吗? 翻开源码,我们可以看到@Data这个接口 RetentionPolicy 是SOURCE级别的,也就是说,在代码编译的时候,相关的注解信息就已经丢掉了,并不会被加载进 JVM 里,那么为什么我们又会在 Compile 代码的时候看见那些 get/set 方法呢?这就不得不说另一种注解解析方式了——编译时解析
...
抛砖引玉 在文章开始前,先看看一个常见的情况 👇
在集团内进行开发时,通常会遇到不同组之间的合作,如果是同一个组的前后端,因为交互请求都是在同一个 「域」 内发生的,所以一般不会存在跨域问题。但如果未做处理,直接从 a.alibaba.com 请求 b.alibaba.com 的接口,就会出现跨域的问题,这是因为浏览器对于不同域请求的限制问题,其实跨域的问题很好解,只要设置了正确的请求头即可,具体的可以参考我的这篇文章 👉《一次跨域问题的分析》
但这是访问不需要登录的接口,那如果是从 a.alibaba.com 访问 b.alibaba.com 下的一个需要登录的接口呢?又该如何解决呢?
下文以 A 站点指代 a.alibaba.com,B 站点指代 b.alibaba.com
单系统登录 对于一个 web 应用来说,通信协议通常是 HTTP 协议,该协议是无状态的,也就是说,在请求与请求之间是不会产生关联的。这也就意味着,任何用户都能通过浏览器访问服务器资源,且不会打扰到其他用户。如下图所示 👇
如果想要保护某些资源,比如一些珍贵的学习资料,那就必须限制浏览器的请求,对于服务端来说就是要知道发出这个请求的人是谁,也即让请求变得有「状态」,只不过既然 HTTP 协议无状态,那就让浏览器和服务器之间共同维持一个状态吧,而这就是最常见的——会话机制。
Cookie 和 Session 在会话机制中,最重要的就是 Cookie 和 Session 了,Session 好理解,服务端保存的用来维护某一个用户的状态,浏览器只需用某种方式记录下这个会话的 ID 然后之后每次请求携带即可,想必有小伙伴会发出疑问了,既然是给浏览器携带参数,那么直接在请求参数里携带不是最简单的吗?
的确,将会话 id 作为每一个请求的参数,服务器接收请求自然能解析参数获得会话 id,并借此判断是否来自同一会话,这个思路当然是可以的,只是这种做法的缺点也十分明显,就是请求的 URL 会变得非常长,隐秘性也很差。
而 Cookie 是浏览器用来存储少量数据的一种机制,数据以”key/value“形式存储,并且浏览器发送 http 请求时自动附带 Cookie 信息。此时,有 Cookie 参与的登录请求的流程就变成了下面这样 👇
Cookie 和 Session 的使用原理基本如此,至于这么设置 Cookie,怎么通过 Cookie 校验 Session 就不是本文要说的内容了。有兴趣的可以查阅相资料。
多系统登录 不知道你有没有留意过,如果你在浏览器中登录了百度网盘之后,再打开百度贴吧时就会发现此时你已经登录成功了,这种情况就是本节要说的多系统登录了。
...

前一篇文章我们介绍了 Java 中的两个常见的序列化方式,JDK 序列化和 Hessian2 序列化,本文我们接着来讲述一个后起之秀——Kryo 序列化,它号称 Java 中最快的序列化框架。那么话不多说,就让我们来看看这个后起之秀到底有什么能耐吧。
Kryo 序列化 Kryo 是一个快速序列化/反序列化工具,依赖于字节码生成机制(底层使用了 ASM 库),因此在序列化速度上有一定的优势,但正因如此,其使用也只能限制在基于 JVM 的语言上。
网上有很多资料说 Kryo 只能在 Java 上使用,这点是不对的,事实上除 Java 外,Scala 和 Kotlin 这些基于 JVM 的语言同样可以使用 Kryo 实现序列化。
和 Hessian 类似,Kryo 序列化出的结果,是其自定义的、独有的一种格式。由于其序列化出的结果是二进制的,也即 byte[],因此像 Redis 这样可以存储二进制数据的存储引擎是可以直接将 Kryo 序列化出来的数据存进去。当然你也可以选择转换成 String 的形式存储在其他存储引擎中(性能有损耗)。
由于其优秀的性能,目前 Kryo 已经成为多个知名 Java 框架的底层序列化协议,包括但不限于 👇
Apache Fluo (Kryo is default serialization for Fluo Recipes) Apache Hive (query plan serialization) Apache Spark (shuffled/cached data serialization) Storm (distributed realtime computation system, in turn used by many others) Apache Dubbo (high performance, open source RPC framework) …… 官网地址在:https://github.com/EsotericSoftware/kryo
...

我之前在《聊一聊 RPC》中曾提过什么是序列化和反序列化,当时有说过之后要单独抽出一期来详细聊聊序列化,没想到这一拖竟然拖了一年多,现在来把这个坑补上。由于篇幅较长,本文先主要介绍两种常见的序列化方式——JDK 序列化和 Hessian 序列化。
序列化是什么(What) 百度百科对于 「序列化」 的解释是:
序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。
这么说太抽象了,举一个例子:你如果想让一个女孩子知道你喜欢她,你可以给她写情书,这样 「喜欢」 这种状态信息就变成了 「文字」 这种可以存储或传输的信息。
至于怎么把“情书”送给女生就有很多种方式了,我在《聊一聊 RPC》中已经有写过了,感兴趣的读者们可以点击阅读。
所以,简单理解序列化就是将“对象”存储的信息保存到某个“文件”中,之后再通过某种方式读取“文件”转换成对象。在 Java 中,序列化其实就是把一个 Java 对象变成二进制内容,本质上就是一个 byte[]数组。
既然有序列化,那么就会有反序列化,在上文的例子中,如果女孩通过情书中的文字明白了男孩的喜欢,这就是一种反序列化。在 Java 中,将一个 byte[]数组重新变成 Java 对象就是一种反序列化。
为什么要序列化(Why) 这个时候肯定就有人会问了,直接把对象作为参数传递不就可以了吗?为什么还要多此一举把对象变成“文本”,然后再将“文本”变成对象?
我们知道,Java 创建的对象都是存在于 Java 虚拟机中,也即 JVM 中,那么 JVM 又在哪里呢?
JVM 是 Java 程序运行的环境,但是他同时是一个操作系统的一个应用程序,即一个进程。他的运行依赖于内存,因此 Java 中对象都是存储在内存中,准确地说是 JVM 的堆或栈内存中,可以各个线程之间进行对象传输,但是无法在进程之间进行传输。如果涉及到跨内存的数据传输(比如两台机器的传输),直接把对象作为参数传递就不可取了,这时就需要通过“网络”将数据传输。
举个例子,如果没办法自己亲自把情书送到对方手上,是不是得找一个人送过去?这就是 RPC 相关的知识了。
怎么序列化(How) 上述内容在之前那篇文章里都有涉及,接下来才是本文的重点,在实际使用时我们究竟该怎么序列化,有哪些方式可以序列化?为什么我们在代码中很少遇到手写序列化的情况。这些都是本文要解答的内容。
本文我们以 Java 为例。
JDK 序列化 作为一个成熟的编程语言,Java 本身就已经提供了序列化的方法了,因此我们也选择把他作为第一个介绍的序列化方式。
JDK 自带的序列化方式,使用起来非常方便,只需要序列化的类实现了Serializable接口即可,Serializable 接口没有定义任何方法和属性,所以只是起到了标识的作用,表示这个类是可以被序列化的。如果想把一个 Java 对象变为 byte[]数组,需要使用ObjectOutputStream。它负责把一个 Java 对象写入一个字节流:
...

计算机的世界是由 0 和 1 构成的,为了方便人类与计算机沟通,先贤们发明了编程语言,通过编译器将这些语言翻译成机器可以看懂的机器语言。为了方便人类更好的阅读代码,避免不必要的 996,几乎所有的编程语言都提供「注释」的特性,在某种程度上,这些「注释」的存在就是“废话”,因为编译器在执行到这里的时候是直接忽略的,「注释」虽然是人类写的,却也只是为了给“愚蠢”的人类看的。然而,无论哪个时代都有前行者,他们所做的不过是让我们的代码看起来更简洁,更有时代的进步感,因此必须要让人类与机器的沟通更进一步了,而这就是写给编译器的注释——「注解」。
何为「注解」 所谓注解,英文名 Annotation,是在 Java SE 5.0 版本中开始引入的概念,同class和interface一样,也属于一种类型。很多开发人员认为注解的地位不高,但其实不是这样的。像@Transactional、@Service、@RestController、@RequestMapping、@CrossOrigin 等等这些注解的使用频率越来越高。
说了这么多,到底何为「注解」?
注解是放在 Java 源码的类、方法、字段、参数前的一种特殊“注释”。
话不多说,直接上代码:
// 用户请求接口 @RestController public class UserController { @GetMapping(value = "/user") public User getUser() { return new User("闰土",22,"男"); } } 上述是一个十分简单的 SpringBoot 的控制器代码,第 1 行是「注释」,是告诉阅读这行代码的人这是一个用户请求接口;第 2 行和第 4 行是「注解」,是用来编译器,这一个 Restful 接口,请求方法为 Get,匹配的是"/user"路径。
注释会被编译器直接忽略,注解则可以被编译器打包进入 class 文件,因此,注解是一种用作标注的“元数据”。从 JVM 的角度看,注解本身对代码逻辑没有任何影响,如何使用注解完全由工具决定。
「注解」的本质 在探究「注解」的本质之前,我们要先理解一个东西,Annotation 同class和interface一样,也属于一种类型,因此如果想要申明一个注解的话,我们同样需要写一个 java 文件来创建注解。注解的创建方法很简单,见下面的代码 👇
import java.lang.annotation.*; @Target(ElementType.METHOD) @Retention(RetentionPolicy.SOURCE) public @interface TestOverride { } 如上面代码所示,创建了一个名为「TestOverride」的注解,关键词是**「@interface」**,这时有小伙伴肯定就要说了,为什么我创建一个注解前还有注解?不急,这里我们暂且按下不表,之后来解释。
...