
前言
对于一个 Java 开发者来说,Lombok 应该是使用最多的插件之一了,他提供了一系列注解来帮助我们减轻对重复代码的编写,例如实体类中大量的 setter,getter 方法,各种 IO 流等资源的关闭、try…catch…finally 模版等,虽然可以通过 IDE 的快捷帮我们生成这些方法,但这些冗长的代码仍会影响代码的简洁性与可阅读性。 如今,随着使用者数量越来越多,Lombok 甚至成为 IDEA 的内置插件了(2020.3 版本+),可见其影响力。
但不知道使用 Lombok 的你,是否思考过这种自动生成代码究竟是什么原理呢?🤔 这些代码又是怎么产生的呢?而这就是本文要展开介绍的内容了。
Lombok 的安装与使用网络上相关的介绍已经很多了,这里就不多说了,自行查阅相关资料即可。
注解解析的两种方式
关于注解,我在之前的文章里有过详细的介绍,在解释 Lombok 的原理之前,推荐你先阅读 👉《给编译器看的注释——「注解」》 这里主要回顾一下 Lombok 注解的解析方式。
运行时解析
这是最常见的注解解析的方式,运行时能够解析的注解,必须将@Retention设置为RUNTIME,这样就可以通过反射拿到该注解。
例如使用最多的@RequestMapping注解就是一个运行时注解。
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Mapping
public @interface RequestMapping {
String name() default "";
@AliasFor("path")
String[] value() default {};
@AliasFor("value")
String[] path() default {};
RequestMethod[] method() default {};
String[] params() default {};
String[] headers() default {};
String[] consumes() default {};
String[] produces() default {};
}
运行时注解的解析原理也很简单,在 java.lang,reflect 反射包中提供了一个接口 AnnotatedElement,该接口定义了获取注解信息的几个方法,Class、Constructor、Field、Method、Package 等都实现了该接口,对反射熟悉的朋友应该都会很熟悉这种解析方式。相关的例子在之前的文章中有介绍过,这里不赘述了。
那 Lombok 的注解也是这种原理吗?
翻开源码,我们可以看到@Data这个接口 RetentionPolicy 是SOURCE级别的,也就是说,在代码编译的时候,相关的注解信息就已经丢掉了,并不会被加载进 JVM 里,那么为什么我们又会在 Compile 代码的时候看见那些 get/set 方法呢?这就不得不说另一种注解解析方式了——编译时解析
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.SOURCE)
public @interface Data {
String staticConstructor() default "";
}
编译时解析
Javac 编译器的编译过程大致可分为 1 个准备过程 3 个处理过程 :
- 初始化插入式注解处理器
- 解析与填充符号表;
- 插入式注解处理器的注解处理;
- 分析与字节码生成。
这 3 个步骤之间的关系如下图所示:

而其中编译期的注解处理有两种机制,分别简单描述下:
Annotation Processing Tool(APT)
APT 自 JDK5 产生,JDK7 已标记为过期,不推荐使用,JDK8 中已彻底删除,自 JDK6 开始,可以使用 Pluggable Annotation Processing API 来替换它,APT 被替换主要有 2 点原因:
- 相关 API 都在 com.sun.mirror 非标准包下
- 没有集成到 javac 中,需要额外运行
Pluggable Annotation Processing API(插件式注解处理器)

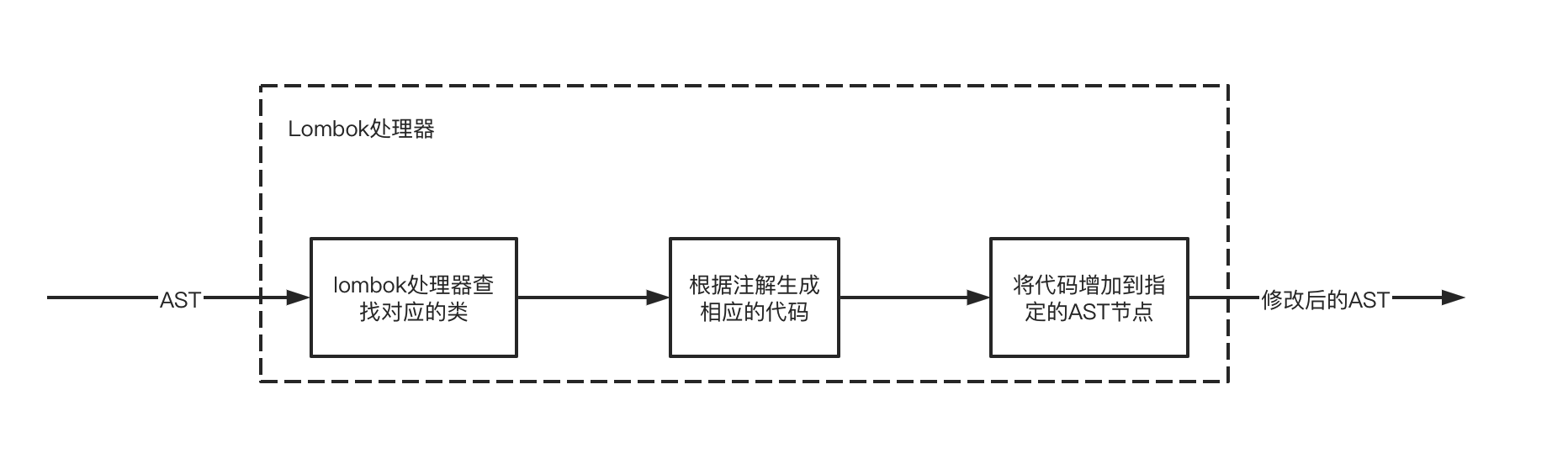
Java6 开始纳入了 JSR-269 规范:Pluggable Annotation Processing API(插件式注解处理器)。作为 APT 的替代方案,JSR-269 提供一套标准 API 来处理 Annotations,并解决了刚才提到的 APT 的两个问题。 在使用 javac 的过程中,它产生作用的具体流程如下所示 👇
-
javac 对源代码进行分析,生成了一棵抽象语法树(AST)
-
运行过程中调用实现了**「JSR 269 API」**的 Lombok 程序
-
此时 Lombok 就对第一步骤得到的 AST 进行处理,找到@Data 注解所在类对应的语法树(AST),然后修改该语法树(AST),增加 getter 和 setter 方法定义的相应树节点
-
javac 使用修改后的抽象语法树(AST)生成字节码文件,即给 class 增加新的节点(代码块)
AST 是一种用来描述程序代码语法结构的树形表示方式,语法树的每一个节点都代表着程序代码中的一个语法结构(Construct),例如包、类型、修饰符、运算符、接口、返回值甚至代码注释等都可以是一个语法结构。
想要实现一个基于**「JSR 269 API」的程序也很容易,**具体来说,我们只需要继承AbstractProcessor类,重写process()方法实现自己的注解处理逻辑,并且在META-INF/services目录下创建javax.annotation.processing.Processor文件注册自己实现的 Annotation Processor,在 javac 编译过程中编译器便会调用我们实现的 Annotation Processor,从而使得我们有机会对 java 编译过程中生产的抽象语法树进行修改。
对于 Java 编译的一些补充
对于 Java 的编译期,其实是一个相对模糊的概念,需要针对具体的情况具体分析。
- 将
*.java文件转为*.class的过程称为编译器的前端(前端编译)。例如:JDK 的 javac 编译器。 - 把字节码(
*.class文件) 转变为 本地机器码 的过程称为 Java 虚拟机的即时编译运行期(JIT 编译器,Just In Time)。例如:HotSpot 虚拟机的 C1、C2 编译器。 - 使用静态的提前编译器(AOT 编译器,Ahead Of Time Compiler)直接把程序变异成与目标及其指令集相关的二进制代码的过程。例如:JDK 的 Jaotc。
他们之间的关系大约是 👇

javac 把 *.java文件编译成*.class文件,*.class文件进入 JVM 后,通过 JIT 编译器将*.class文件解释为对应的机器码。而 AOT 则是直接把*.class文件编译系统的库文件,不再依靠 JIT 去做这个事情。
Javac 这类编译器对代码的运行效率几乎没有任何优化措施,但由于该阶段离程序员编码是最近的(相较于 JIT 而言),所以对于程序员编码来说,前端编译器在编译期的优化更加密切,许多新生的 Java 语法特性,都是靠编译器的**「语法糖」(自动装箱、拆箱与遍历循环)**来实现的,这是因为 Javac 做了很多针对 Java 语言编码过程的优化措施来改善程序员的编码风格、提升编码效率,而不是依赖虚拟机的底层改进来支持。