
背景
实习的时候被问过一个问题,为什么 redis 会有 pipline,mysql 会有 batch,这些东西都具有批量操作的共性,是什么原因让我们在处理数据时需要批量操作?
这么说可能有些抽象,举一个和 API 调用有关的例子 🌰:
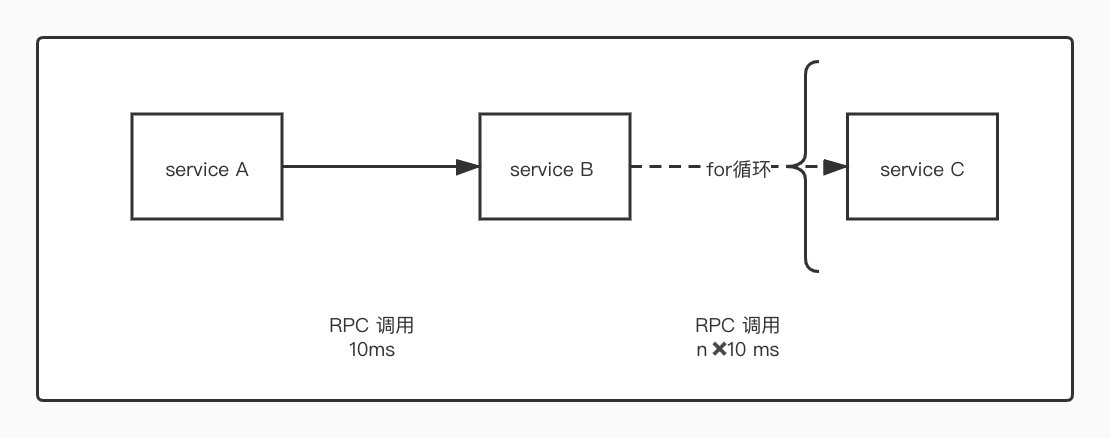
现有三个服务 service A、service B 和 service C。因业务需要,我们需要在 service A 中调用 service B 获取一组 id,然后根据 id 从 service C 中读取最终内容。然后组织成结果返回前端。由于 service C 只提供了单个 id 查询内容的 API,所以如果我们想要获取批量的信息,最先想到的办法是通过 for 循环多次调用 service C。但是这样的办法是极其不优雅的,接下来我们从以下两个方面来分析。
网络通信
鉴于现在的分布式架构,每个 service 都分布在不同的服务、不同的机器中,所以我们每次调用都要通过 RPC 来实现,这就要求我们不得不构造同等数量的请求来获取数据。这样就会导致了一些效率问题。如下图所示:
所以我们通常会通过在 service C 中提供一个批量查询的接口来解决多次通信的问题。如下图所示 👇
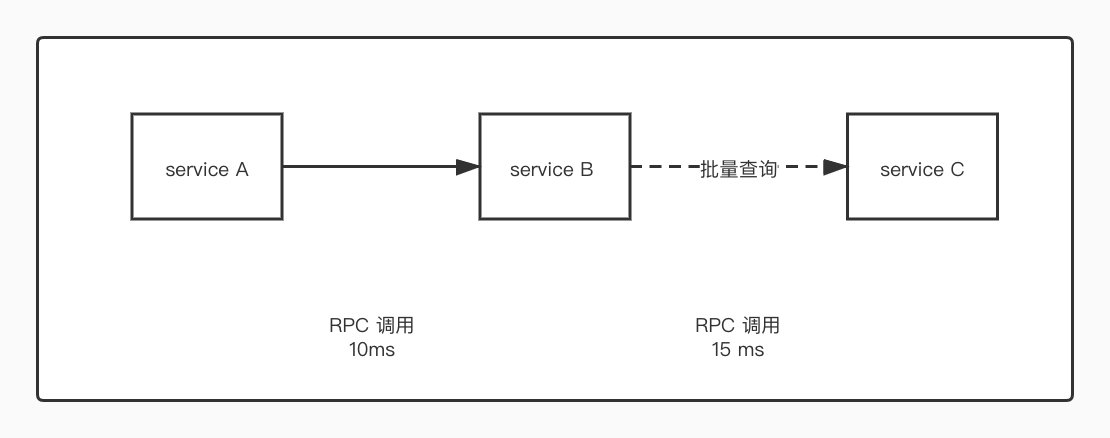
我们知道,并不是每一次网络传输都非常稳定,中途可能会遇到丢包等一系列问题,而用批量查询代替 for 循环单个查询,这样做的好处是,我们可以减少网络通信的次数,一定程度上可以增加整个系统的健壮性。
数据查询
解释完多次 rpc 调用可能造成的网络延迟的问题后,我们再往深一点的地方看。
一般情况下,数据都是存放在数据库中的,所以无论是单个查询还是批量查询,我们最终都是要访问到数据库的。
现假设,我们需要从数据库中查询一个 id 为 123 的用户信息,我们可以用类似下面这样的代码。
long id = 123;
Person p = serviceA.getPersonById(id);
那如果我们需要查询一组 id 为 123、456、789 的用户信息,在没有批量查询接口的情况下,我们可以用 for 循环的方式实现:
long[] ids = {123,456,789};
List<Person> ps=new ArrayList<>();
for(long id : ids){
ps.add(serviceA.getPersonById(id));
}
这么看虽然符合逻辑,但在数据库查询时,会有一定的性能损耗。
以 MySQL 为例,不论是 MyISAM 存储引擎还是 InnoDB 存储引擎,锁这个概念一直都是贯穿其中的,MyISAM 存储引擎默认是使用表锁,InnoDB 存储引擎默认使用的是行锁,这就意味着,在查询数据时,mysql 会将相关记录“锁起来”,只有当结果查询完毕时才会释放锁。
相较于批量查询只有一次上锁、开锁这种情况,循环里的每次查询都要先拿到锁,然后再释放锁,这个操作自然会更加耗时。这也就是为什么 mysql 会提供 batch 操作的原因。
Redis 中的 pipline
这里我们再来扩展一下,为什么 redis 中会需要 pipline 这样一种实现机制。
pipline,中文翻译为管道,它可以将一组 redis 命令进行封装,一次性将多个命令传输到 redis 服务端,并将数据一次性带回。这样就可以通过一次 RTT (Round Trip Time 往返时间),将多个数据带回,减少了数据传输的 RTT 消耗。如下图所示 👇
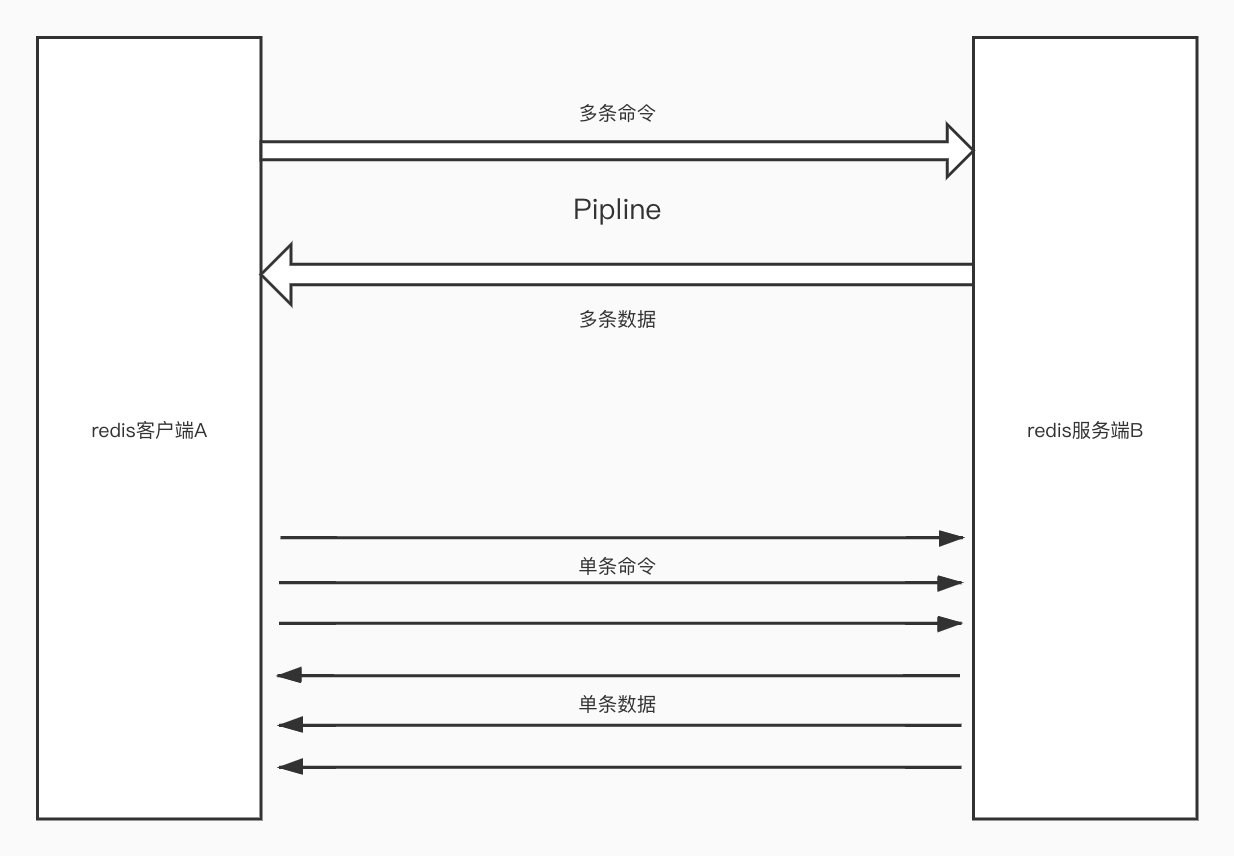
redis 的命令执行是微妙级别的,这个速度相对于网络延时是非常小的,因此才有了 redis 的性能瓶颈在网络的说法。并且事实上网络确实已经是 redis 的性能瓶颈之一。
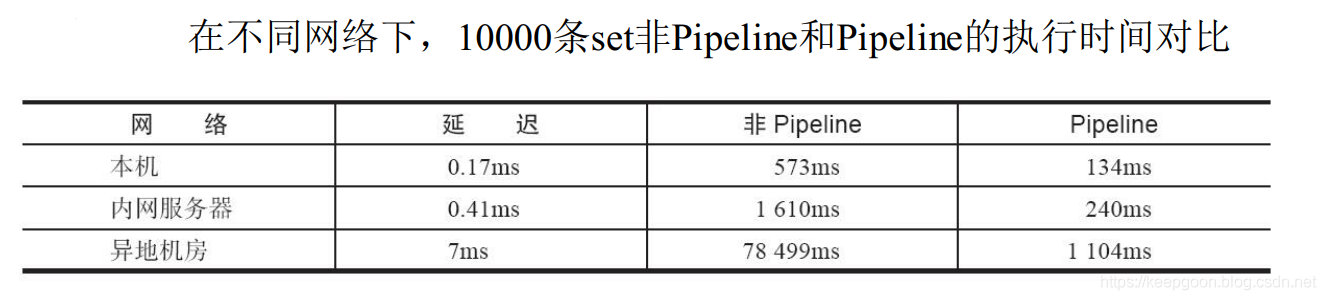
这就更凸显了批量操作的重要性了。
最后
回到这一篇的主题,为什么我们需要批量操作?
虽然现在已经是“云”的时代,在云内部的 rpc 请求几乎不消耗时间,但我们仍然需要意识到构造请求、解析请求、查询数据库等方面的时间和资源消耗。
如果不能批量操作,那么,需要操作的资源越多,操作执行的次数也会越多。这是一个线性上升的模型。就像数据库导入数据,一条两条,手写个 sql 完全没问题。那如果是,100 万+数据呢?一条一条手动导入?这显然是不合理的。
这就是批量操作的现实意义。
