
看到标题大家可能还会有些诧异,这不是才刚刚国庆吗,怎么都开始写双十一的文章了。的确,虽然国庆还没有过完,但今年淘宝的双十一活动已经开始了。

我的上一篇文章是在 9 月 12 日发布的,直至今日一直没有更新的主要原因就是这半个月全身心的投入到这次双十一项目的研发中了。这半个月一个字总结下来就是 「累」,不仅仅是身体上的累,更有心理上的累。
短短半个月的时间,几十个令人无语的需求,没完没了大大小小的会议以及根本写不完的代码在前半个月疯狂摧残着我,不知多少个夜晚回到家已是第二天,一觉醒来继续重复着昨日的行为,总是会让我怀疑在这里工作的意义。
不过好在 10 月 1 日 0 点,这次的活动平稳上线了。虽然还有很多功能之后才会陆续上线,但连续半个月的连轴转总算是有暂缓脚步的迹象了,我也终于可以趁着这个国庆假期简单分享一下我来淘宝的第一个双十一了。
双十一活动
2009 年 11 月 11 日,是淘宝的第一个双十一,自那时起,每年的 11 月 11 日变成淘宝的一个固定节日(当然现在各种平台都会凑一下双十一的热度)。不过那一年我还小,我第一次听说双十一是在大学的时候,那个时候对一些电子产品感兴趣,双十一会有很大的优惠力度,不过可能是我的购物习惯导致的,蹲点抢购我一般是不会参与的。但是第二天我总还是会关注一下公开披露的数据,比如交易峰值,QPS 这些,毕竟是专业所致。去年实习因为个人原因没参与到双十一就离职回学校了,今年 7 月正式加入淘宝后,我迎来了自己的第一个双十一。
我所在的部门今年的双十一活动名为 「双十一种草机」,目前这个活动已经上线了,手机淘宝扫描上方二维码即可体验。其需要解决的问题痛点是 「想参与双十一,但是又不知道买什么」 。看到这可能有的人就要说了,整这么多花里胡哨的干嘛,直接像 PDD 一样,百亿补贴直接减免不就行了吗?
额,对于这点,我只能说,我就是一个写代码的,领导说要做啥那就做啥。至于为什么不直接像 PDD 一样直接减免如下图所示 👇

功能开发
我负责的功能是种草机活动的干预模块,其实要做的事情并不是很复杂,在不同时间段运营人员会根据当前情况对种草推荐/结果做一些紧跟时事的干预,比如增加某些优质内容的曝光量,或者拉黑某个劣质明星及其相关内容,一些敏感词过滤等等,大致流程如下图所示。
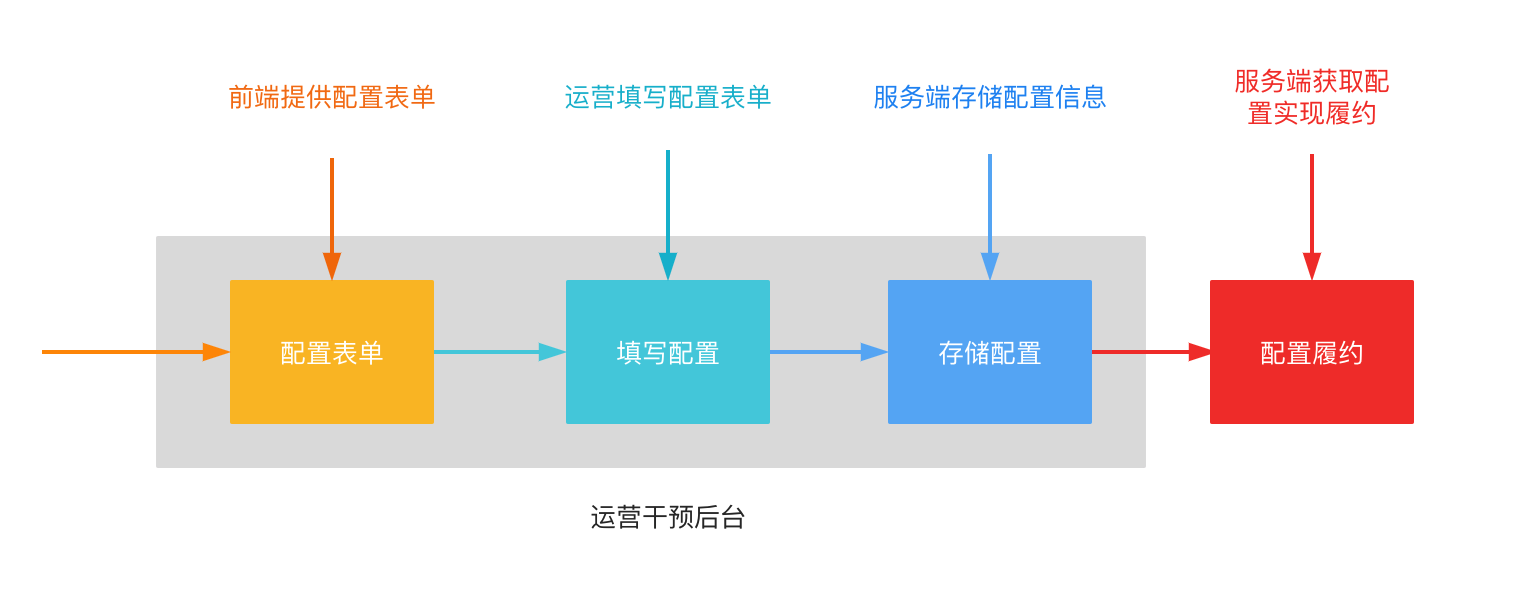
运营在某一个干预后台上可以进行一些配置的填写,前端同学负责搭建这个后台的页面,服务端同学需要将运营填写的配置数据落库,然后在前台履约的时候拿出这些数据。乍一看,确实没什么难点,不就是一个简单的 CRUD 功能吗?难不成阿里的双十一就这么简单吗?

后台数据落库
为了使整个干预模块形成一个闭环,我们需要从 后台数据落库 和 前台数据履约 两个角度去考虑实现运营干预。
对后台数据落库而言,的确就是配置数据的 CRUD,但难点在于对配置 数据的抽象。运营的配置需求千变万化,究竟是以何种方案实现成为了一个难点。如果每一类配置都作为一张表,那未来这个数据库将会出现 “数据表爆炸” 的情况,而且配置与配置之间并不是独立的,是有可能存在某种关联关系的,因此数据表的设计必须能够做到针对此类需求的通用性、易扩展。
其实本来写到这里的时候我是准备了一张简化后的数据模型图,但考虑到数据安全的问题,这里就用文字简单说明了,下一部分的前台履约同样。

可以说明的是,对于干预配置,设计的核心理念是 「一切都是配置」。在设计中,我们将一份运营配置分为两类属性:基础属性和表单属性。基础属性很好理解,如 ID、名称、操作人员、投放人群、投放时间等这些每个配置都会考虑到的东西。表单属性即运营后台呈现出来的需要运营填写的奇奇怪怪的属性,例如拉黑配置中的黑名单词,指定搜索词的头像等。
对于运营配置的基本属性以 树形结构 存储数据,通过 ParentId 指定配置之间的父子关系,通过 Group 指定配置类别,再通过唯一主键明确一个配置。采用树形结构存储将会天然支持此类运营配置的业务需求,理解起来也会更加自然。
对于运营配置的表单属性,这一块是变化最多且最不通用的地方,借鉴了 Schema-Free(模式自由) 的设计理念。之所以会考虑到 Schema-Free,是由于这一类表单数据 无需被索引,并且千变万化,妄图通过某一种抽象去描述几乎是不可能的。当然这种方式也是有好有坏的,好处是扩展性强,坏处就是如果需要被索引,改动成本较高。 所以在开发时,我有做过如下的吐槽:
脱离实际业务需求来做顶层设计就是空中阁楼,不切合实际。
私以为做架构设计的目的是为了 化繁为简,虽然「抽象」可以解决大部分耦合问题,但如果在不明确设计目标的前提下,为了抽象而抽象,为了设计而设计,反而会让一个原本并不复杂的架构引入更多莫名其妙的概念从而变得复杂。
其次,任何架构设计都有其局限性,在不同阶段的业务诉求/技术诉求不同,在设计时的侧重点自然也会不同。因此,对一个系统来说,没有最好的架构设计,只有最适合的架构设计,妄图通过一个设计解决所有问题是不现实的。
前台数据履约
前台数据的履约是这段时间最折磨我的几件事情之一了。奇奇怪怪的需求大多数都来自这一部分,在这一块,我们收到了来自用户的请求后,读取落库的配置信息,并作出干预。理论上流程确实很容易,但是有几个问题值得思考下。
并发量
无论多么不起眼的代码,一旦被放大到被几千万甚至上亿的人执行到,都有随时翻车的风险,在阿里做开发,并发量是无论什么时候都需要考虑到的问题。如果只是简单的从数据库中读取配置信息,以现在的 QPS 随时会把数据库打挂,因此缓存是必须的,只不过缓存雪崩,缓存击穿,数据一致性等问题同样也会接踵而至。
实时性
干预配置是否能够实时生效,是一个非常重要的点,因为这关系到运营人员对双十一活动的节奏把握。考虑到干预配置的实时性,我将干预分为 服务端干预 和 算法引擎干预 两大类。

举个例子,如果我们需要拉黑某个词条的搜索结果则需要在调用算法引擎结果前直接干预,这样做的好处是可以减少一次算法资源的调用,且效果是实时生效的。但如果我们需要拉黑某个搜索结果下面的某一条内容(比如某些性暗示视频),这个干预究竟是放在服务端做还是算法引擎呢?理论上二者都可以,但是干预效果却不一样,比较如下:
- 服务端干预,及时拉黑,但算法返回结果被拉黑后,前台展示会缺少数据(例如,应该返回 10 条数据干预后只返回了 9 条)
- 算法引擎干预,有超时的风险,干预生效有延时,但返回结果不会缺少数据。
因此,又回到了上一节所说的,没有最好的架构设计,只有最适合的架构设计。
其实在实际开发过程中,又涉及到很多问题,如算法引擎的超时,服务端干预与算法引擎干预的强耦合问题等,为了解决这些问题,我们又引入了 「图数据库」,但随即又出现了 幂等、系统可用性 等问题,这里也不方便做出详细解释。
小结
作为一个技术专栏,本文花了很大的篇幅在讲述此次双十一我的一些开发工作,但其实这一部分个人觉得并不是非常重要,因为这一块更多还是编码的活,如果只是单纯的编码其实是一件很快乐的事情,发现问题、思考问题、解决问题这些是不会让人心累的。真正让人难受的,是整个氛围,只是这一块我不便多谈。
总的来说,通过这一次双十一活动,我学到了非常非常多的东西,也暴露出很多问题,现在正值国庆长假,虽然作为双十一的第一枪的种草机活动已经上线,但还有很多功能没有发布,真正的双十一也还没有到来,等到所有的活动结束后,再从非技术的视角完整的复盘一下我的第一个双十一。